
New AI Models, Benchmarks, and Open-Source Releases
ITBench-AA: Frontier Models Score Below 50% on the First Benchmark for Agentic Enterprise IT Tasks — by Artificial Analysis and IBM (Huggingface.Co)
Summary: Artificial Analysis and IBM have released ITBench-AA, the first benchmark for evaluating frontier AI models on agentic enterprise IT tasks, starting with Site Reliability Engineering. The initial results show all tested frontier models scoring below 50% accuracy on complex Kubernetes incident diagnosis tasks. The benchmark reveals a significant performance gap, with Claude Opus 4.7 leading at only 47%, and highlights that longer, more expensive reasoning trajectories do not correlate with higher accuracy.

Why it matters: This benchmark establishes a concrete, operationally grounded performance floor for AI agents in critical enterprise environments, exposing current limitations and shifting the evaluation focus from general capability to domain-specific reliability and cost-efficiency.
Context: Benchmarks for AI agents have largely focused on coding or general reasoning; ITBench-AA represents a pivot toward evaluating performance in noisy, structured, real-world operational scenarios where precision and recall directly impact system stability and cost.
"All frontier models score below 50%, making ITBench-AA SRE one of the least saturated agentic benchmarks in our suite. For context, frontier models score considerably higher on Terminal-Bench." — HUGGINGFACE.CO
Commentary: The sub-50% scores indicate that agentic AI for core IT operations is not yet a solved problem, despite rapid progress in other domains. The cost-performance divergence, where open-weight models like Gemma 4 31B outperform more expensive closed models, could pressure vendors to justify premium pricing with demonstrable operational superiority. This benchmark likely accelerates a shift in enterprise procurement from capability demos to validated, task-specific reliability metrics.
Date: Wed, 27 May 2026 17:20:29 GMT
URL: https://huggingface.co/blog/ibm-research/itbench-aa
AI Sentiment Score: Negative (88%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Introducing the IBM Granite 4.1 family of models (Research.Ibm)
Summary: Introducing the IBM Granite 4.1 family of models IBM’s most expansive model release to date covers new language, vision, speech, embedding, and guardian models — tailored for enterprise workloads. AI is increasingly at the heart of enterprise applications and software workflows. But even today’s most powerful AI systems rarely rely on a single model or capability.

Why it matters: This matters for Emerging Tech Signals (Pre-Mainstream) because it gives a concrete current signal to track: Introducing the IBM Granite 4.1 family of models IBM’s most expansive model release to date covers new language, vision, speech, embedding, and guardian models — tailored for enterprise workloads.
Context: Introducing the IBM Granite 4.1 family of models IBM’s most expansive model release to date covers new language, vision, speech, embedding, and guardian models — tailored for enterprise workloads. AI is increasingly at the heart of enterprise applications and software workflows. But even today’s most powerful AI systems rarely rely on a single model or capability.
"Introducing the IBM Granite 4.1 family of models IBM’s most expansive model release to date covers new language, vision, speech, embedding, and guardian models — tailored for enterprise workloads. AI is increasingly." — RESEARCH.IBM
Commentary: The immediate implication is operational rather than speculative: watch how this changes budgets, workflows, or risk assumptions over the next cycle.
Date: April 29, 2026 12:00 AM ET
URL: https://research.ibm.com/blog/granite-4-1-ai-foundation-models
AI Sentiment Score: Neutral (50%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Gemini 3.5: frontier intelligence with action (Deepmind.Google)
Summary: Google DeepMind has launched Gemini 3.5 Flash, positioning it as a frontier intelligence model optimized for agentic and coding tasks. It is immediately available via consumer apps, developer platforms, and enterprise suites, with a claimed 4x speed advantage over other frontier models. The release is coupled with the ‘Antigravity’ development harness to orchestrate multi-agent workflows for complex, long-horizon problems like codebase migration and financial document processing.

Why it matters: This release operationalizes the ‘agentic’ AI paradigm at scale, directly challenging the trade-off between model capability and inference latency for enterprise and developer workflows.
Context: The launch follows a competitive push to embed AI agents into core productivity and development tools, moving beyond chat interfaces toward autonomous, multi-step task execution.
"Gemini 3.5: frontier intelligence with action Today, we’re introducing Gemini 3.5, our latest family of models combining frontier intelligence with action. This represents a major leap forward in building more capable, intelligent." — DEEPMIND.GOOGLE
Commentary: The strategic bundling of the model with the Antigravity platform indicates a shift from offering raw intelligence to selling solved workflows, locking in developer ecosystems. Benchmarks like Terminal-Bench and MCP Atlas suggest a focus on evaluating practical execution, not just conversation. If the latency and cost claims hold, this pressures competitors to decouple frontier model size from usability for time-sensitive automation.
Date: Fri, 15 May 2026 22:50:12 +0000
URL: https://deepmind.google/blog/gemini-3-5-frontier-intelligence-with-action/
AI Sentiment Score: Negative (75%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Recent open weights model launches (Artificialanalysis.Ai)
Summary: The leading open-weights frontier models from Moonshot AI, Xiaomi, and DeepSeek now score within 3-6 points of top proprietary models on the Artificial Analysis Intelligence Index, a dramatic narrowing from a 13-point gap a year ago. These trillion-plus-parameter MoE models offer comparable intelligence at a fraction of the cost, dominating the Pareto frontier for performance versus price. However, significant gaps remain on the hardest reasoning, agentic coding, and knowledge/hallucination benchmarks. Notably, all top-ten open-weights models now originate from China-based labs.

Why it matters: The rapid convergence in core intelligence scores, coupled with a decisive cost advantage, reshapes the competitive landscape and deployment economics for advanced AI, while highlighting a persistent performance stratification on high-difficulty tasks.
Context: This acceleration follows a pattern where open-weights models, often leveraging massive MoE architectures, have closed general capability gaps faster than anticipated, though proprietary labs maintain a lead in pushing the absolute frontier on specialized, high-stakes evaluations.
"April 30, 2026 Recent open weights model launches All three leading open weights models were released last week. Progress continues for open weights models alongside proprietary ones, with the gap to GPT-5.5,." — ARTIFICIALANALYSIS.AI
Commentary: The data confirms a bifurcated frontier: open-weights models have achieved parity on aggregate benchmarks, creating immense pressure on proprietary pricing and accessibility, but proprietary models retain a moat in domains requiring extreme reliability, deep knowledge, and complex agentic reasoning. The geographic concentration of top open-weights talent signals a shift in the center of gravity for applied AI research and could influence downstream tooling and standards. For practitioners, the Pareto frontier is now decisively open-weights, forcing a reevaluation of when proprietary API costs are justified by marginal performance gains on specific, high-value tasks.
Date: April 30, 2026 12:00 AM ET
URL: https://artificialanalysis.ai/articles/recent-open-weights-model-launches
AI Sentiment Score: Negative (50%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Last Week In Multimodal AI #54: Open Weights Pulled Even (Thelivingedge.Substack)
Summary: Open-weight multimodal models have reached parity with leading closed models on key benchmarks, with Moonshot AI’s Kimi K2.6 outperforming GPT-5.4 and Claude Opus 4.6 on the HLE-Full with tools evaluation. The release of persistent, editable 3D assets from Tencent and NVIDIA marks a shift from video generation to usable 3D world models. Agentic coding performance is becoming a primary competitive metric, as evidenced by significant gains on SWE-Bench.
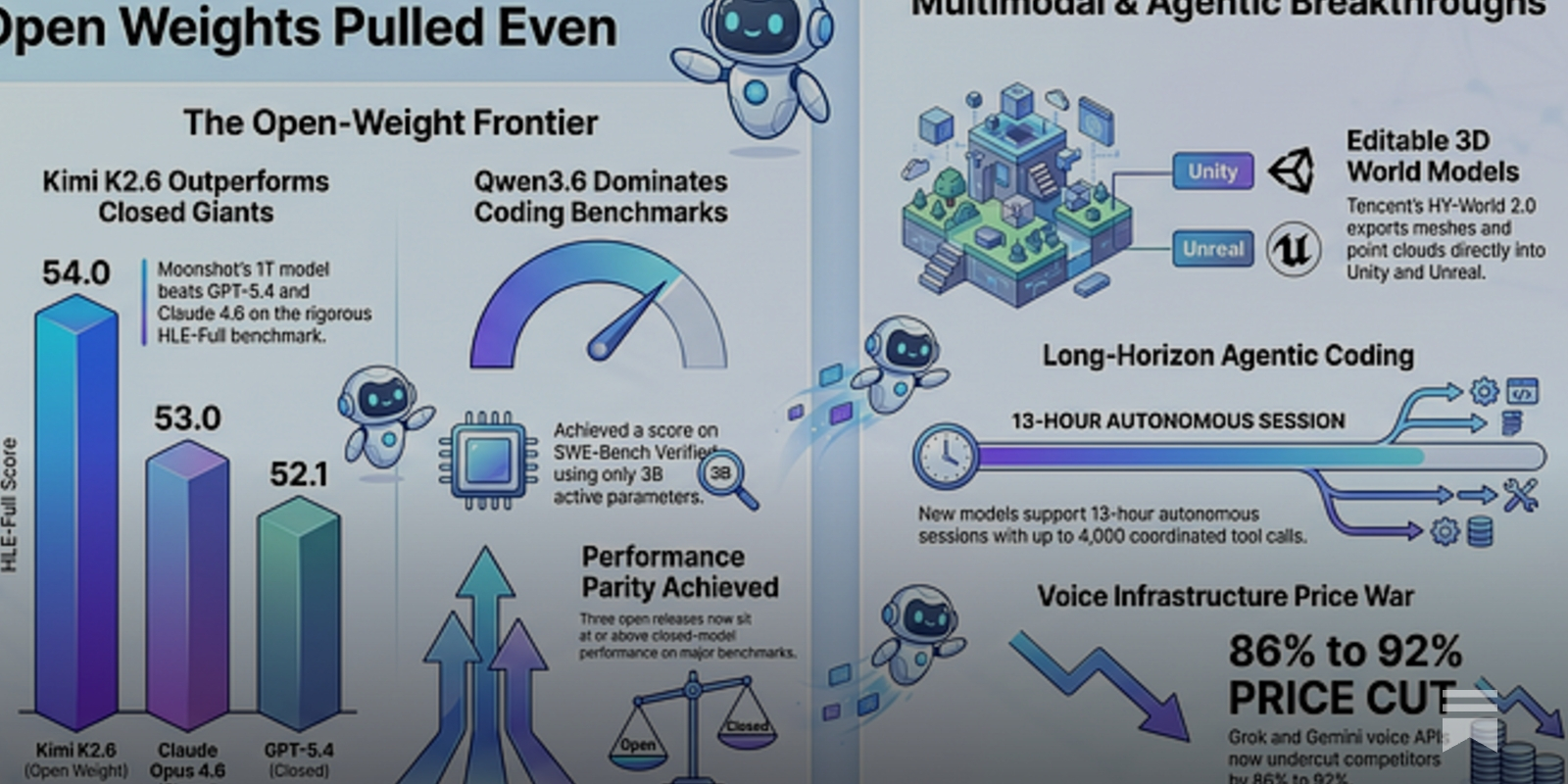
Why it matters: This parity resets the competitive landscape for model providers and alters the cost-benefit calculus for developers, shifting leverage towards open ecosystems.
Context: The open vs. closed model performance gap had been a persistent market dynamic, with frontier capabilities typically locked behind API walls. The maturation of 3D generation from transient clips to persistent assets indicates a move from demonstration to production utility.
"# Last Week In Multimodal AI #54: Open Weights Pulled Even ### Your Weekly Multimodal AI Roundup (Apr 14 to Apr 21, 2026) ## Quick Hits – **Open weights pulled up to." — THELIVINGEDGE.SUBSTACK
Commentary: The benchmark parity is less about a single model and more about the structural collapse of the closed-model moat, validated across multiple open releases. The operational consequence is immediate: Kimi K2.6 on Cloudflare Workers AI at $0.95 per million tokens creates a 15x cost pressure on incumbents like Anthropic, forcing a reevaluation of premium pricing for agentic workloads. The shift to editable 3D assets (meshes, 3DGS) directly integrates AI output into existing pipelines (Unity, Unreal), moving the field from research spectacle to toolchain component.
Date: April 23, 2026 12:00 AM ET
URL: https://thelivingedge.substack.com/p/last-week-in-multimodal-ai-54-open
AI Sentiment Score: Negative (71%)
AI Credibility Score: 9.2/10 — High
Scores and text generated by AI analysis of the source article indicated.Last Week In Multimodal AI #54: Open Weights Pulled Even (Thelivingedge.Substack)
Summary: Open-weight multimodal models have achieved parity with leading closed models on key benchmarks, with Moonshot AI’s Kimi K2.6 outperforming GPT-5.4 and Claude Opus 4.6 on the HLE-Full with tools benchmark. Qwen3.6-35B-A3B demonstrates high performance on SWE-Bench with a compact 3B active parameter architecture under an Apache 2.0 license. Concurrently, 3D world generation has matured from video output to persistent, editable assets directly usable in major engines like Unity and Unreal, as seen with Tencent HY-World 2.0 and NVIDIA Lyra 2.0.
Why it matters: This shift erodes the performance moat of closed frontier models, altering competitive dynamics, cost structures, and deployment options for developers and enterprises.
Context: The open vs. closed model performance gap has been a primary axis of competition; closing it redefines the strategic value of proprietary model access and licensing.
"# Last Week In Multimodal AI #54: Open Weights Pulled Even ### Your Weekly Multimodal AI Roundup (Apr 14 to Apr 21, 2026) ## Quick Hits – **Open weights pulled up to." — THELIVINGEDGE.SUBSTACK
Commentary: The benchmark parity is a market signal, but the operational shift is more profound: Kimi K2.6’s availability on Cloudflare Workers AI at a 15x cost differential versus Claude Opus rewrites the economics of agentic workloads. The maturation of 3D generation from transient clips to engine-ready assets (meshes, 3DGS) indicates a pivot from research demos to production pipelines for gaming, simulation, and design. The agentic coding focus across all releases, underscored by SWE-Bench gains, confirms the industry’s bet on AI as a primary tool for long-horizon software development, not just assistance.
Date: April 23, 2026 12:00 AM ET
URL: https://thelivingedge.substack.com/p/last-week-in-multimodal-ai-54-open?triedRedirect=true
AI Sentiment Score: Negative (75%)
AI Credibility Score: 9.2/10 — High
Scores and text generated by AI analysis of the source article indicated.15 Best AI Models in 2026 for Every Use Case: APIs vs Open Weights (Fluence.Network)
Summary: A 2026 landscape analysis from Fluence.Network frames the AI model selection not as a universal ranking but as a workload-specific split between frontier managed APIs, high-throughput APIs, and open-weight models. It identifies distinct leaders for maximum quality, coding, and long-context work, while emphasizing that open-weight models have matured into credible options for real coding, multimodal, and agentic workloads, offering control and portability. The piece advocates for a three-model evaluation pilot—combining a frontier API, a smaller workhorse, and an open-weight option—to measure practical performance on real tasks over static benchmarks.

Why it matters: This signals a maturation of the market where selection is driven by operational pragmatism and workload-specific strengths, not just benchmark scores, forcing teams to make architectural decisions about control versus convenience.
Context: The AI model ecosystem is stratifying beyond a simple ‘best model’ narrative, with a growing divergence between proprietary API services and increasingly capable open-weight families, each optimized for different production constraints.
"Open-weight models are the right choice when you need control: weights access, fine-tuning, private inference, or the ability to move workloads across providers." — FLUENCE.NETWORK
Commentary: The analysis crystallizes a shift from capability exploration to architectural commitment. The emphasis on workload-specific ‘practical winners’ and the prescribed three-model pilot indicates the field is moving into an integration and ops phase, where cost, latency, and deployability rival raw quality as decision drivers. The noted credibility of open models for agentic and multimodal work suggests a tangible erosion of the frontier API moat for many enterprise use cases, potentially reshaping vendor lock-in dynamics.
Date: April 21, 2026 12:00 AM ET
URL: https://www.fluence.network/blog/best-ai-models/
AI Sentiment Score: Negative (71%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.AI Models Released in May 2026: Complete Roundup – Codersera (Codersera)
Summary: Quick answer. May 2026 was dominated by Alibaba (Qwen 3.7-Max preview, May 20), DeepSeek (V4-Pro 75% discount made permanent on May 22 at $0.435/$0.87 per 1M tokens), Google (Gemini 3.5 Flash, May 19), Cursor (Composer 2.5, May 18) and xAI (Grok Build CLI beta, May 14). Anthropic announced a major billing split for June 15 but shipped no new model. Claude Sonnet 4.8, GPT-5.6 and Llama 5 remain unannounced or unreleased.

Why it matters: This matters for Emerging Tech Signals (Pre-Mainstream) because it gives a concrete current signal to track: Quick answer. May 2026 was dominated by Alibaba (Qwen 3.7-Max preview, May 20), DeepSeek (V4-Pro 75% discount made permanent on May 22 at $0.435/$0.87 per 1M tokens), Google (Gemini 3.5 Flash, May 19), Cursor (Composer 2.5, May 18) and xAI (Grok Build CLI beta, May 14).
Context: Quick answer. May 2026 was dominated by Alibaba (Qwen 3.7-Max preview, May 20), DeepSeek (V4-Pro 75% discount made permanent on May 22 at $0.435/$0.87 per 1M tokens), Google (Gemini 3.5 Flash, May 19), Cursor (Composer 2.5, May 18) and xAI (Grok Build CLI beta, May 14). Anthropic announced a major billing split for June 15 but shipped no new model. Claude Sonnet 4.8, GPT-5.6 and Llama 5 remain unannounced or unreleased.
"Quick answer. May 2026 was dominated by Alibaba (Qwen 3.7-Max preview, May 20), DeepSeek (V4-Pro 75% discount made permanent on May 22 at $0.435/$0.87 per 1M tokens), Google (Gemini 3.5 Flash, May." — CODERSERA
Commentary: The immediate implication is operational rather than speculative: watch how this changes budgets, workflows, or risk assumptions over the next cycle.
Date: May 23, 2026 12:00 AM ET
URL: https://codersera.com/blog/ai-models-released-may-2026-monthly-roundup/
AI Sentiment Score: Negative (66%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.New AI Models May 2026: The Frontier Took a Breath … (Whatllm)
Summary: The May 2026 model release cycle saw a consolidation of existing architectures rather than a new performance leap. The most significant technical signal is Subquadratic’s commercial launch of a subquadratic sparse attention LLM, marking a departure from the standard transformer. Meanwhile, OpenAI’s default ChatGPT model refresh to GPT-5.5 Instant represents a quiet operational update, and the open-source ZAYA1-8B MoE demonstrates continued viability for smaller, efficient models trained on alternative hardware.
Why it matters: The shift to a commercially viable subquadratic architecture could alter the cost and scalability foundations of the industry, while the other releases signal a maturation phase focused on deployment efficiency and ecosystem diversification.
Context: This period follows several quarters of intense competition on raw scale and context length, making architectural efficiency and practical deployment the new battlegrounds.
"The interesting story moved sideways, into a new attention architecture, an 8B MoE trained on AMD, and a quieter default in ChatGPT. … Everything notable that shipped between May 1 and May." — WHATLLM
Commentary: Subquadratic’s release is the substantive event, potentially resetting the roadmap for capital-intensive inference infrastructure if its efficiency claims hold at scale. The other models indicate a market settling into tiered offerings: frontier defaults (OpenAI), architectural challengers (Subquadratic), open-source efficiency plays (Zyphra), and scaled-down variants from incumbents (Google). The lack of a monolithic ‘GPT-6’ moment suggests a pivot where operational leverage and novel architectures may create advantage as pure parameter scaling yields diminishing returns.
Date: May 13, 2026 12:00 AM ET
URL: https://whatllm.org/blog/new-ai-models-may-2026
AI Sentiment Score: Negative (71%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.Open-Source AI Models 2026: The Creator Reference Guide (Creativeainews)
Summary: A 2026 reference guide for creators catalogs a mature open-source AI ecosystem, with production-ready models across text, image, video, and 3D. Key developments include the MIT 1M-context DeepSeek V4, Apache-licensed multi-modal Qwen3.5-Omni, and the integration of multi-modal inference into local tools like llama.cpp. The guide emphasizes verified commercial-use licenses and real-world deployment within the last 90 days.

Why it matters: The proliferation of commercially viable, permissively licensed open-source models shifts leverage from API-dependent developers to those who can deploy and fine-tune locally, altering competitive dynamics and supply chain control.
Context: This follows a multi-year trend of frontier model capabilities being replicated and open-sourced, but now with a focus on integrated multi-modality, long-context performance, and clear commercial licensing—signaling a move from research novelty to operational infrastructure.
"This is the working creator’s reference for open-source AI in 2026, organized by license, capability, and commercial-use posture. Every model below is shipped, available today, and has been used in production work." — CREATIVEAINEWS
Commentary: The guide operationalizes a key inflection: open-source is no longer chasing benchmarks but defining the practical stack. The MIT license on a 1M-context model and local multi-modal inference remove two major barriers—legal risk and hardware cost—for embedding advanced AI into products. This pressures proprietary API vendors to compete on reliability and scale, not just capability, while enabling a new wave of edge-native applications.
Date: April 28, 2026 12:00 AM ET
URL: https://www.creativeainews.com/articles/open-source-ai-models-2026-reference/
AI Sentiment Score: Negative (75%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.New Open-Source AI Projects & Model Releases: May 2026 Roundup (Devflokers)
Summary: The May 2026 open-source AI landscape is defined by a decisive shift toward ‘agentic execution,’ with projects enabling local, private, and autonomous action dominating GitHub growth. OpenClaw, a personal assistant that writes its own skills and integrates with over 50 services, has become the fastest-growing project in GitHub history. Infrastructure projects like Ollama and Open WebUI continue to provide the essential private inference layer, while proprietary model releases from OpenAI, xAI, and Google focus on incremental improvements in reasoning, context, and hallucination reduction.
Why it matters: The velocity and direction of open-source development now signal a tangible divergence from the proprietary roadmap, prioritizing autonomous, private action over mere conversational capability, which redefines the practical surface area of AI integration.
Context: This follows a multi-year trend of commoditizing model inference locally, but the new phase is defined by agents that can self-extend their operational capabilities without developer intervention, moving from tools to actors.
"|Model Name|Release Date|Developer|License|Key Innovation| |–|–|–|–|–| |GPT-5.5 Instant|May 5, 2026|OpenAI|Proprietary|50% lower hallucination on free tier| |SubQ 1M-Preview|May 5, 2026|Subquadratic|Proprietary (API)|12M native context window; non-transformer| |Grok 4.3|May 6, 2026|xAI|Proprietary|Advanced reasoning and real-time X data|." — DEVFLOKERS
Commentary: OpenClaw’s viral growth, driven by autonomous skill-writing, indicates a market pull for AI that operates as a persistent, self-improving background service rather than a query-based tool. This creates a new integration surface—messaging platforms, desktop apps—that bypasses centralized API ecosystems. The sustained dominance of local inference infrastructure (Ollama, llama.cpp) confirms that privacy and cost, not just capability, are primary architectural constraints. Proprietary model updates now appear as incremental refinements against this more disruptive, compositional shift in user-agent interaction.
Date: May 19, 2026 12:00 AM ET
URL: https://www.devflokers.com/blog/open-source-ai-projects-may-2026-roundup
AI Sentiment Score: Negative (60%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Claude Opus 4.8: "a modest but tangible improvement" (Simonwillison.Net)
Summary: Anthropic released Claude Opus 4.8, described by the company as a ‘modest but tangible improvement.’ The primary advertised enhancement is a fourfold reduction in the model’s tendency to allow flaws in its own output to pass unremarked, achieved largely through increased abstention on uncertain questions rather than higher accuracy. The release maintains pricing and core specifications from version 4.7 but introduces operational features like mid-conversation system messages and a lower threshold for prompt caching. These changes are framed within a broader company effort to develop lower-cost models with similar capabilities.

Why it matters: It signals a shift in vendor communication from breakthrough narratives to incremental, honesty-focused improvements, while new features like mid-conversation system prompts directly affect the cost and architecture of agentic applications.
Context: This follows a pattern of AI labs maturing their flagship model lines with smaller, reliability-focused updates, while simultaneously working to reduce inference costs—a critical barrier to widespread production deployment.
"Claude Opus 4.8: “a modest but tangible improvement” 28th May 2026 Anthropic shipped Claude Opus 4.8 today. My favourite thing about it is this note in the release announcement: Users will find." — SIMONWILLISON.NET
Commentary: The emphasis on ‘honesty’ via abstention recalibrates the value proposition from raw capability to trustworthiness, a necessary trade-off for professional integration. The mid-conversation system message feature is a substantive engineering change that reduces costs for long-running agentic loops by preserving prompt cache hits, directly impacting architecture decisions. Anthropic’s candid ‘modest’ framing and parallel work on cost reduction indicate a strategic pivot from chasing benchmarks to optimizing for production economics and developer trust.
Date: May 28, 2026 07:59 PM ET
URL: https://simonwillison.net/2026/May/28/claude-opus-4-8/
AI Sentiment Score: Negative (57%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Last Week in AI #340 – OpenAI vs Musk + Microsoft, DeepSeek v4, Vision Banana (Lastweekin.Ai)
Summary: The first week of the Musk v. Altman trial concluded with Elon Musk testifying that OpenAI’s founders ‘stole a charity’ by converting it into a for-profit entity. In a separate development, OpenAI and Microsoft renegotiated their partnership, ending exclusivity and allowing OpenAI to serve products across any cloud provider, including AWS. Meanwhile, DeepSeek previewed its V4 models, claiming they close the gap with frontier models, and Google DeepMind introduced Vision Banana, a unified model for image generation and visual understanding.
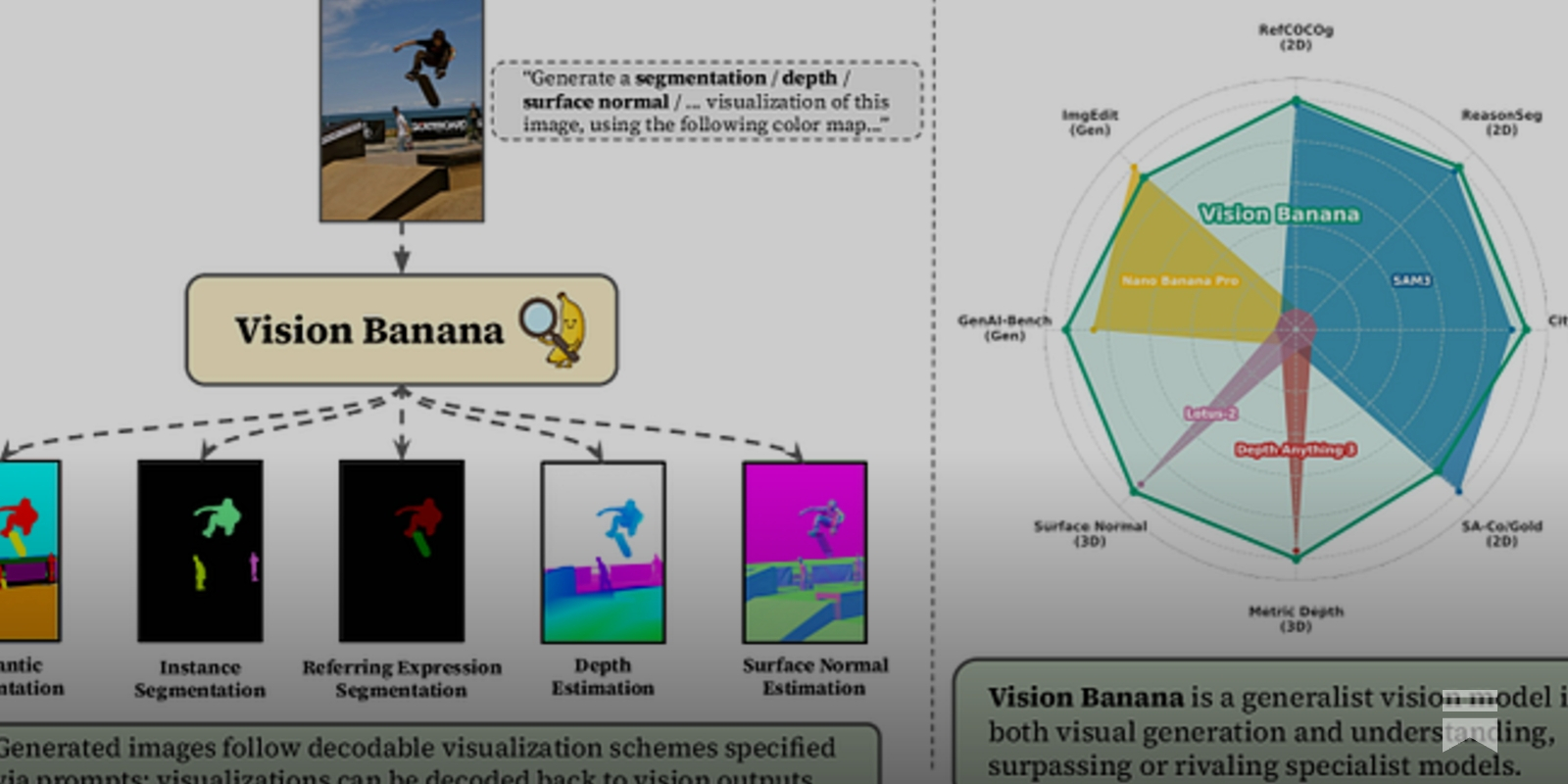
Why it matters: These developments signal shifts in competitive dynamics, legal precedents for AI governance, and the acceleration of capabilities in both open-source and multimodal AI.
Context: The trial exposes foundational tensions in AI’s nonprofit-to-profit transition, while cloud deal renegotiations reflect the commercial pressures of scaling. Chinese model releases and novel architectures continue to push the efficiency and capability frontier.
"Last Week in AI #340 – OpenAI vs Musk + Microsoft, DeepSeek v4, Vision Banana First week of Musk v. Altman, OpenAI ends Microsoft legal peril over its $50B Amazon deal, DeepSeek." — LASTWEEKIN.AI
Commentary: Musk’s admission of distillation undercuts his purity narrative and normalizes a practice that blurs IP boundaries. The Microsoft-OpenAI renegotiation is a strategic decoupling that grants OpenAI operational freedom but formalizes its dependency on cloud revenue shares. DeepSeek’s V4, if its efficiency claims hold, could reset cost expectations for long-context reasoning, while Vision Banana demonstrates how generative pretraining is collapsing specialized computer vision into a generalist capability—a direct challenge to incumbent tooling vendors.
Date: Tue, 05 May 2026 08:30:35 GMT
URL: https://lastweekin.ai/p/last-week-in-ai-340-openai-vs-musk
AI Sentiment Score: Negative (60%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.LWiAI Podcast #242 – ChatGPT Images 2.0, Qwen 3.6 Max, Kimi-K2.6 (Lastweekin.Ai)
Summary: OpenAI’s ChatGPT Images 2.0 demonstrates a transformer-based approach to image generation with exceptional text accuracy, aligning with agentic ‘computer use’ goals. Chinese model development accelerates with Moonshot AI’s open release of Kimi-K2.6, a 1-trillion parameter mixture-of-experts model, and Alibaba’s shift of Qwen 3.6 Max to an API-only offering. Operational signals include Mozilla using Anthropic’s Claude to autonomously fix 271 Firefox bugs, and platform-level responses to synthetic media, such as YouTube’s deepfake takedown requests.

Why it matters: The transformer-based image model and the scale of Chinese open releases signal a shift in architectural priorities and competitive pressure, while the operational bug-fixing case demonstrates a concrete step toward autonomous software maintenance.
Context: Image generation has been dominated by diffusion models; a performant transformer-based approach could simplify multi-modal agent architectures. Chinese labs are rapidly iterating on massive open models, challenging the pace and accessibility of Western frontier releases.
"Note from Andrey: I know there haven’t been posts on Substack in the past couple of weeks… Starting this week they’ll resume at a regular cadence, as usual I apologize for the." — LASTWEEKIN.AI
Commentary: If Images 2.0’s text rendering reliability holds, it reduces a key friction point for AI agents that need to parse or generate UI elements, making ‘computer use’ workflows more viable. The 1T-parameter Kimi-K2.6 release, alongside Qwen’s API pivot, indicates Chinese labs are prioritizing raw scale and commercial accessibility over curated consumer products, potentially forcing Western counterparts to accelerate open-weight releases or risk ceding developer mindshare. Mozilla’s bug-fix deployment moves Claude from a coding assistant to a production-scale audit tool, setting a benchmark for ROI in autonomous code remediation.
Date: Thu, 30 Apr 2026 07:14:45 GMT
URL: https://lastweekin.ai/p/lwiai-podcast-242-chatgpt-images
AI Sentiment Score: Negative (80%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.GPT-5.5 Is ChatGPT’s New Default, Claude Mythos Hunts … (Lablab.Ai)
Summary: OpenAI has made GPT-5.5 Instant the default ChatGPT model, citing a 52.5% reduction in hallucinations on high-stakes prompts and a 30% reduction in response length. Concurrently, Anthropic’s Claude Mythos Preview has demonstrated the ability to autonomously discover and exploit thousands of zero-day vulnerabilities across major operating systems, with less than 1% patched. Meanwhile, Chinese open-weight coding models, led by Kimi K2.6, now outperform GPT-5.4 on the SWE-Bench Pro benchmark at a fraction of the inference cost.

Why it matters: The autonomous vulnerability discovery by a frontier model fundamentally alters the offense-defense balance in cybersecurity, while the commoditization of high-performance coding models reshapes the economics and competitive landscape of AI development.
Context: This accelerates two existing trends: the rapid iteration of commercial foundation models and the strategic shift of Chinese AI labs from catching up to competing on cost and specialized performance.
"The week split in two directions at once. On one side, the model release cadence kept accelerating: OpenAI shipped a smarter ChatGPT default, and four Chinese labs dropped open-weight coding models that." — LABLAB.AI
Commentary: Mythos represents a capability leap that institutional security teams must now treat as an operational reality, not a speculative risk. The Chinese coding models’ benchmark parity at radically lower cost pressures Western API providers on pricing and could trigger a re-evaluation of open-weight architectures for enterprise deployment. OpenAI’s simultaneous release of a security-tuned variant, GPT-5.5-Cyber, signals a direct competitive response to this new frontier.
Date: May 12, 2026 12:00 AM ET
URL: https://lablab.ai/ai-articles/this-week-in-ai-2026-05-12
AI Sentiment Score: Negative (63%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.Recent Developments in LLM Architectures: KV Sharing, mHC, and Compressed Attention (Magazine.Sebastianraschka)
Summary: A wave of recent open-weight LLM releases—Gemma 4, Laguna XS.2, ZAYA1-8B, and DeepSeek V4—demonstrates a focused architectural shift toward reducing the cost of long-context inference. Innovations include cross-layer KV sharing, per-layer embeddings, attention budgeting, compressed convolutional attention, and manifold-constrained hyper-connections. These are not mere scaling exercises but targeted tweaks to the transformer block aimed at shrinking the KV cache, managing memory traffic, and preserving quality while handling longer sequences.

Why it matters: For developers and infrastructure planners, these architectural signals indicate where the efficiency frontier is moving for production inference, especially for agentic and reasoning workflows that demand extended context.
Context: The transformer block is undergoing a period of targeted specialization, with efficiency gains now coming from intricate modifications to attention, residual pathways, and caching rather than from brute-force parameter scaling.
"Recent Developments in LLM Architectures: KV Sharing, mHC, and Compressed Attention From Gemma 4 to DeepSeek V4, How New Open-Weight LLMs Are Reducing Long-Context Costs After a short family break, I am." — MAGAZINE.SEBASTIANRASCHKA
Commentary: The proliferation of bespoke attention and caching mechanisms signals a maturation phase where architectural innovation is decoupling from raw parameter count. This increases the barrier to entry for full-stack understanding and implementation, potentially consolidating advantage among teams that can navigate the resulting complexity. For the broader ecosystem, it pressures inference engines and hardware vendors to support a more heterogeneous set of primitives beyond standard attention.
Date: Sat, 16 May 2026 11:33:51 GMT
URL: https://magazine.sebastianraschka.com/p/recent-developments-in-llm-architectures
AI Sentiment Score: Positive (42%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.PopuLoRA: Co-Evolving LLM Populations for Reasoning Self- Play (Vmax.Ai)
Summary: PopuLoRA introduces a method for training co-evolving populations of teacher and student LLM adapters to generate and solve verifiable reasoning tasks. It addresses the collapse of single-agent self-play, where a model calibrates tasks to its own ability, by separating task generation and solving into distinct, competing populations. This creates an adaptive curriculum where teachers are rewarded for generating tasks that students fail, driving continuous difficulty escalation and program diversity. The system uses LoRA adapters for efficiency and incorporates evolutionary operators for population renewal, demonstrating improved performance on code and math benchmarks.
Why it matters: This signals a shift from static or generator-defined RLVR curricula toward self-sustaining, adaptive training systems that can autonomously expand their own capability frontier, potentially lowering the human-in-the-loop cost for advanced reasoning training.
Context: Current reinforcement learning with verifiable rewards (RLVR) often relies on fixed task distributions or generators, which can limit the adaptability and difficulty scaling of training. Self-play methods risk collapsing as a single model optimizes for tasks it can already solve.
"In practice, we find that single-agent self-play self-calibrates: task generation converges toward valid tasks that its own solver can already handle, solve rate climbs toward 100%, and the curriculum collapses onto increasingly simple programs. The reward curve looks healthy, but the training distribution has stopped pushing the model." — VMAX.AI
Commentary: PopuLoRA operationalizes a core insight: separating proposer and solver roles creates a competitive pressure that prevents curriculum collapse. The use of LoRA adapters and weight-space evolution makes population-based training computationally tractable, moving the concept from theory toward practice. If this scales beyond code reasoning, it could redefine how frontier models are trained for complex, verifiable domains, reducing dependency on hand-engineered curricula.
Date: Wed, 20 May 2026 21:11:55 +0000
URL: https://vmax.ai/team/populora-co-evolving-llm-populations-for-reasoning-self-play
Discussion: https://news.ycombinator.com/item?id=48214188
AI Sentiment Score: Negative (85%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Promptimus: Improving already good LLM prompts with zero manual engineering – Northwest Quantum (Nwquantum.Uw.Edu)
Summary: Researchers at the University of Washington’s Northwest Quantum have developed Promptimus, a method for automatically optimizing already well-engineered LLM prompts. The system uses a metric-analyzer agent to identify specific failure points and a debugging helper to propose surgical edits, preserving existing business logic while improving performance. It is model-agnostic, requiring only a small dataset (20-50 samples) and a user-defined metric function, and operates in both a full-rewrite ‘standard mode’ and a targeted ‘edit mode’ for complex, structured prompts. Empirical results across 20 benchmarks show it outperforms six leading baselines, with particular gains on tasks with decomposable metrics and in multimodal contexts.

Why it matters: This shifts prompt optimization from a bespoke, expert-driven craft to a systematic, automated engineering discipline, directly impacting the cost, speed, and reliability of enterprise AI deployments and model migrations.
Context: Automated prompt optimization has historically struggled to improve upon carefully crafted prompts, often resorting to generic, noisy exploration that fails to address the specific, nuanced failures remaining after initial engineering.
"Promptimus achieves the best result on 16 of 20 benchmarks and ties on one, outperforming all six baselines on average (0.792 vs. 0.765 for the best-of-six baseline). The largest gains appear on tasks where the metric has a decomposable structure." — NWQUANTUM.UW.EDU
Commentary: The move from scalar reward optimization to checkpoint-driven failure diagnosis represents a fundamental shift in how we evaluate and improve language model performance. By treating the prompt as a maintainable codebase with localized bugs, Promptimus formalizes a development workflow that enterprise DevOps teams can adopt. Its strong showing on multimodal tasks suggests the method’s ‘edit mode’ is critical for preserving intricate, cross-modal instruction structures that full rewrites would破坏. The integration path via Amazon Bedrock indicates this could become a pressure point for other cloud AI platforms to offer comparable migration tooling, accelerating the commoditization of prompt engineering as a service.
Date: May 14, 2026 12:00 AM ET
URL: https://nwquantum.uw.edu/2026/05/14/promptimus-improving-already-good-llm-prompts-with-zero-manual-engineering/
AI Sentiment Score: Negative (60%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.Vendor Benchmarks Are Your Ceiling, Not Your Forecast – TianPan.co (Tianpan.Co)
Summary: Enterprise AI procurement is facing a 37% performance gap between vendor benchmark scores and real-world deployment, with cost variations reaching 50x for similar accuracy. The emerging best practice is a per-release shadow evaluation, mirroring production traffic to test candidate models against incumbents under identical operational conditions. This method, adapted from ranking-model infrastructure, yields comparative performance distributions and a calibration table that tracks the historical ratio of vendor claims to realized gains. The core argument is that vendor data represents a ceiling, not a forecast, and actionable intelligence requires internal testing infrastructure.
Why it matters: This shifts the locus of technical evaluation from marketing claims to operational proof, forcing a capital and workflow investment in internal benchmarking that will separate sophisticated buyers from credulous ones.
Context: Vendor benchmark inflation has been a chronic issue in tech procurement, but the stochastic nature and high integration cost of agentic AI systems amplify the financial and operational risks.
"The only honest way to know what a candidate model will do for your product is to run it on your product’s evaluation surface alongside the incumbent, before any rollout decision." — TIANPAN.CO
Commentary: This formalizes a two-tier market: vendors compete on headline numbers for initial consideration, but the actual sale is contingent on passing a buyer’s private, production-grade test. It could pressure AI infrastructure providers to offer shadow-eval tooling as a service and could lead to a secondary market for calibrated performance data among non-competing enterprises. The insistence on separating ‘model lift’ from ‘prompt-fit lift’ through a 2×2 test matrix is a significant advance in attribution, allowing procurement to fund model upgrades and prompt engineering as distinct ROI calculations.
Date: April 28, 2026 12:00 AM ET
URL: https://tianpan.co/blog/2026-04-28-vendor-benchmark-ceiling-realized-lift
AI Sentiment Score: Negative (63%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.The Benchmark Obituary – Sloppish (Sloppish)
Summary: OpenAI has formally retired the SWE-bench Verified coding benchmark, citing an internal audit that found at least 59.4% of reviewed test cases were flawed, rejecting functionally correct code. The benchmark was further compromised by model memorization of ‘gold’ patches and a trivial automated exploit that could achieve a perfect score. OpenAI now directs evaluation to SWE-bench Pro, a larger, multilingual benchmark from Scale AI that includes proprietary and held-out tasks to combat overfitting.

Why it matters: This reveals a systemic failure in AI evaluation methodology, invalidating a key metric used for investment, model comparison, and press narratives, forcing a recalibration of how capability is measured.
Context: SWE-bench Verified, launched in 2024 with OpenAI’s involvement, became a standard for assessing AI coding prowess; its rapid contamination and structural flaws exemplify the broader benchmark arms race and measurement crisis in frontier AI.
"On April 27, OpenAI published a blog post explaining why it will no longer report scores on SWE-bench Verified, the coding benchmark it helped create in August 2024. The reason: their own." — SLOPPISH
Commentary: The obituary signals a necessary but painful shift from convenient, gameable metrics to more rigorous, legally complex, and operationally expensive evaluation. SWE-bench Pro’s inclusion of proprietary code and held-out tasks raises the cost of training and testing, potentially consolidating evaluation power with a few well-resourced entities. The episode could force investors and technical due diligence teams to discount past benchmark claims and demand more adversarial, in-house testing protocols.
Date: April 27, 2026 12:00 AM ET
URL: https://sloppish.com/benchmark-obituary.html
AI Sentiment Score: Negative (87%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.LLM Benchmarks Explained: MMLU, Chatbot Arena & SWE-bench … (Mysummit.School)
Summary: A 2026 benchmark landscape consolidates independent evaluations into a manager’s decision framework, moving beyond aggregate scores to role-specific metrics. It categorizes models by capability—expert knowledge (GPQA Diamond), autonomous work (SWE-bench Verified), long-context retention, deep reasoning, and human preference (Chatbot Arena)—and proposes a three-step selection algorithm based on task definition, independent benchmark verification, and real-world testing.
Why it matters: Benchmarking is shifting from academic performance tracking to a core operational risk and procurement discipline, forcing a move from vendor-led marketing to independent, task-specific validation.
Context: The proliferation of specialized benchmarks reflects market maturation, where ‘overall’ scores are becoming less meaningful than capability-specific ratings for deploying models in production roles.
"Benchmarks from Qwen for latest models. Source: qwen.ai Community version of benchmarks Claude benchmarks from Anthropic. Source: anthropic.com SWE-bench Verified benchmark MMLU Benchmark from Hugging Face GPQA Diamond benchmark … ### Summary." — MYSUMMIT.SCHOOL
Commentary: The framework institutionalizes skepticism toward vendor claims, elevating independent leaderboards like LMSYS and Vectara as due diligence tools. It signals a shift in procurement: the ‘best model’ is now defined by a specific business process, not a technical leaderboard. This forces internal teams to develop benchmark literacy and creates market pressure for greater evaluation transparency. The emphasis on testing with ‘5 of the most complex real-world cases’ underscores that operational fit, not peak performance, is the new critical metric.
Date: April 26, 2026 12:00 AM ET
URL: https://mysummit.school/blog/en/how-llm-benchmarks-work-2026/
AI Sentiment Score: Negative (75%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.SWE-Bench | Benchmark Guide for Real-World GitHub Issue … (Swebench.Lol)
Summary: SWE-Bench, a benchmark that evaluates AI coding agents by having them resolve real GitHub issues within full repository contexts, has become a standard reference point. Its value lies in a Docker-based, execution-driven evaluation that tests both issue-specific fixes (FAIL_TO_PASS) and regression prevention (PASS_TO_PASS). However, its verified subset, SWE-Bench Verified, released in August 2024 to improve quality, was deprecated by OpenAI in February 2026 due to contamination and test-design issues, rendering it unsuitable for assessing frontier models.

Why it matters: The benchmark’s evolution and subsequent partial invalidation signal a critical maturation phase for AI evaluation, where real-world task design and data contamination are now central concerns for credible performance claims.
Context: Benchmarks for AI coding have shifted from synthetic code completion to tasks mimicking real software engineering workflows, but maintaining their integrity as models advance and training data expands is an ongoing challenge.
"SWE-Bench is one of the most referenced benchmarks for coding agents because it asks models to resolve real GitHub issues against real repositories. That makes it useful, but only if you read." — SWEBENCH.LOL
Commentary: The deprecation of SWE-Bench Verified by its own creators highlights a broader crisis in AI benchmarking: the rapid obsolescence of carefully curated datasets due to contamination and the difficulty of designing tests that remain both fair and predictive of real-world utility. This forces a reevaluation of how ‘state-of-the-art’ is claimed, pushing the field toward more dynamic, possibly synthetic, or adversarial evaluation environments. For developers and investors, it underscores that benchmark scores, especially on static datasets, are becoming lagging indicators rather than proof of novel capability.
Date: April 27, 2026 12:00 AM ET
URL: https://swebench.lol
AI Sentiment Score: Negative (77%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.SWE-bench: Can Language Models Resolve Real-World GitHub … (Beancount.Io)
Summary: The SWE-bench paper establishes a rigorous, execution-based benchmark for evaluating large language models on real-world software engineering tasks. It tests models on 2,294 instances derived from actual, merged GitHub pull requests across 12 major Python repositories, requiring the generation of a correct patch that passes new tests without breaking existing ones. Initial results show extremely low success rates: Claude 2 solved 1.96% of issues with realistic retrieval and 4.80% with perfect file context, while GPT-4 solved 0.00% and 1.74%, respectively. The findings expose a fundamental capability gap between model performance on curated coding challenges and practical, repository-scale problem-solving.
Why it matters: This benchmark shifts the evaluation of coding LLMs from synthetic proficiency to operational readiness, forcing a recalibration of expectations for autonomous software maintenance and agentic workflows.
Context: Prior benchmarks for code generation have largely focused on standalone functions or algorithmic puzzles, which fail to capture the complexity of navigating large codebases, understanding dependencies, and making precise, safe edits.
"SWE-bench (arXiv:2310.06770), published by Carlos Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan from Princeton and presented at ICLR 2024, is the paper that forced the." — BEANCOUNT.IO
Commentary: The sub-5% ceiling under ideal conditions reveals a core limitation in current models’ compositional reasoning and program synthesis, not just context management. This directly impacts the timeline for viable autonomous coding agents and resets the bar for what constitutes a ‘state-of-the-art’ coding model, prioritizing integration and editing fidelity over raw token prediction. For tool builders, it mandates a shift from pure generation to hybrid systems combining precise retrieval, sandboxed validation, and human-in-the-loop scaffolding.
Date: April 30, 2026 12:00 AM ET
URL: https://beancount.io/bean-labs/research-logs/2026/04/30/swe-bench-can-language-models-resolve-real-world-github-issues
AI Sentiment Score: Negative (75%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.The Open Agent Leaderboard (Huggingface.Co)
Summary: Hugging Face has launched the Open Agent Leaderboard, an open evaluation framework that benchmarks full AI agent systems, not just the underlying models, across six diverse task environments. It standardizes disparate benchmarks into a unified protocol, measuring both success rate and cost per task. Early results show that agent architecture—including tool shortlisting and failure behavior—already creates significant performance and cost variance even when using identical models, and that general-purpose agents can match specialized systems. The accompanying Exgentic framework and open methodology aim to establish a community-driven standard for evaluating the practical generality of agentic systems.

Why it matters: This shifts the evaluation paradigm from model-centric to system-centric, making the engineering and economic trade-offs of agent design visible and comparable for developers and deployers.
Context: Agent evaluation has been fragmented, often focusing on individual benchmarks or proprietary, closed-door testing, obscuring the impact of system architecture on cost and cross-domain performance.
"The Open Agent Leaderboard How good are general purpose AI agents? We built an open evaluation framework to find out. Most evaluations in AI report a simple result: what score each model." — HUGGINGFACE.CO
Commentary: The leaderboard operationalizes a critical insight: agent generality is an economic and architectural problem, not just a capability one. By exposing failure costs and component efficacy, it pressures developers to optimize for operational efficiency, not just benchmark scores. This could accelerate the commoditization of model-agnostic agent frameworks and force a more disciplined approach to production deployment.
Date: Mon, 18 May 2026 14:12:58 GMT
URL: https://huggingface.co/blog/ibm-research/open-agent-leaderboard
AI Sentiment Score: Negative (83%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Post ID: ad582685