AI Agents, Automation, and Developer Tools
Product Hunt Weekly 2026-05-21: AI Agents Go Full Execution, Memory Layer Infrastructure Rises, Google Gemini Omni Targets Video (Shareuhack)
Summary: The Product Hunt Top 20 for the week of May 21, 2026, is dominated by a shift from AI as an advisory tool to AI as an autonomous executor, with products like PollyReach, StoreClaw, and Fere AI handling phone calls, e-commerce operations, and crypto trades. This execution-layer focus is paralleled by the emergence of memory layer infrastructure projects—OpenHuman, Agentmemory, LobeHub—addressing the critical challenge of agent persistence. Meanwhile, Cursor’s Composer 2.5 demonstrates that open-source base models with task-specific fine-tuning can match top-tier performance at a fraction of the cost, and Google’s Gemini Omni positions video generation as a new subscription gateway.

Why it matters: The transition from AI assistants to AI executors reshapes business models from per-seat SaaS to per-result services, while the memory layer becomes a foundational infrastructure battle with implications for data ownership, agent coordination, and developer lock-in.
Context: This follows a maturation curve where AI capability is now assumed; the competitive frontier has moved to reliable execution, persistent context, and operational cost.
"Product Hunt Weekly 2026-05-21: AI Agents Go Full Execution, Memory Layer Infrastructure Rises, Google Gemini Omni Targets Video Data Period: 2026-05-14 ~ 2026-05-21 Sources: Product Hunt API, Hacker News, WebSearch TL;DR: This." — SHAREUHACK
Commentary: The execution-layer shift forces a re-evaluation of vertical SaaS defensibility, as agents bypass the human-in-the-loop interface entirely. Memory infrastructure’s divergent approaches—personal, tool, team—signal a pre-standards scramble where the winning data format may capture more value than the AI models themselves. Cursor’s cost-performance breakthrough validates a disaggregated model stack, pressuring generalist incumbents on economics, not just benchmarks.
Date: May 21, 2026 12:00 AM ET
URL: https://www.shareuhack.com/en/posts/product-hunt-weekly-2026-05-21
AI Sentiment Score: Negative (71%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Product Hunt Weekly 2026-04-23: AI Agent Infrastructure Boom … (Shareuhack)
Summary: The April 23 Product Hunt rankings reveal a bifurcation in AI’s trajectory: Anthropic’s rapid-fire product releases (Claude Opus 4.7, Claude Code Desktop, Claude Design, Claude Desktop Buddy) signal a platform consolidation push, while open-source projects like Moonshot’s Kimi K2.6 demonstrate state-of-the-art multi-agent coordination. The top product, however, is the Dune keypad, a physical hardware interface for AI workflow switching, indicating a maturation phase where AI capability seeks tangible, ergonomic expression. This is underscored by other hardware-adjacent entries like the SpeakON MagSafe voice device and the Claude Desktop Buddy BLE API.

Why it matters: The shift from pure software to integrated hardware interfaces and the concurrent platform vs. open-source competition redefine the points of control and value capture in the emerging agentic stack.
Context: Product Hunt’s weekly leaderboard has historically served as a leading indicator for developer and early-adopter sentiment, often preceding mainstream venture and product trends by 6-18 months.
"# Product Hunt Weekly 2026-04-23: AI Agent Infrastructure Boom, Platform Wars Heat Up, Hardware Revival … TL;DR: The biggest story this week is Anthropic shipping four products in rapid succession (Claude Opus." — SHAREUHACK
Commentary: The Dune keypad’s top ranking is a concrete market signal that the latency and cognitive load of managing multiple AI agents and contexts is becoming a bottleneck, creating demand for physical, tactile solutions. Anthropic’s multi-product blitz and the high placement of tools like Resend CLI 2.0 and Codex 2.0 suggest a race to own the foundational workflows—coding, communication, design—before they fragment. The presence of Kimi K2.6 and InstantDB shows the open-source counter-pressure is focusing on specific, high-leverage capabilities (massive agent coordination, instant backend provisioning) rather than general model parity.
Date: April 23, 2026 12:00 AM ET
URL: https://www.shareuhack.com/en/posts/product-hunt-weekly-2026-04-23
AI Sentiment Score: Positive (50%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Open-Source Tooling Launches Are Getting More Operational (Insights.Reinventing.Ai)
Summary: A convergence in open-source AI agent frameworks is shifting focus from experimental autonomy to production-ready operational patterns. Major projects like LangGraph, OpenAI’s Agents SDK, PydanticAI, and CrewAI are now emphasizing durable execution, structured handoffs, human-in-the-loop checkpoints, and built-in observability. This reflects a market move away from API churn and toward hardening for maintainable execution, particularly for small teams and creators. The practical signal is the standardization of implementation patterns around staged workflows and explicit reliability controls.

Why it matters: For operators, the bottleneck has shifted from model capability to maintainable execution; this tooling convergence lowers the barrier to deploying reliable, auditable agent systems in production.
Context: This follows a period of fragmentation in agent frameworks, where demos prioritized autonomy over operational discipline, leaving a gap for small teams needing to integrate AI into daily workflows.
"The strongest AI agents trend this week is not a single model release. It is the acceleration of open-source agent tooling that makes day-to-day operations easier for small teams. Across major repositories,." — INSIGHTS.REINVENTING.AI
Commentary: This standardization prefigures a ‘prompt-to-workflow’ packaging phase, where successful chat interactions can be formalized into versioned pipelines. It signals a maturation where evaluation, rollback, and human oversight become baseline expectations, not advanced features. The explicit migration path from AutoGen to the Microsoft Agent Framework is a telling market correction, prioritizing sustainable operations over novelty.
Date: May 14, 2026 12:00 AM ET
URL: https://insights.reinventing.ai/articles/ai-agents-open-source-tooling-launches-2026-05-14
AI Sentiment Score: Negative (66%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.AI Agent Industry Weekly: News, Products, and Deployment Signals … (Zengineer.Blog)
Summary: The agent layer is crystallizing as a distinct operational and commercial tier, separate from model performance. OpenAI’s Realtime API models add low-latency audio reasoning and tool-calling, while Anthropic’s financial services templates and Microsoft’s collaboration frameworks signal a shift toward packaged, accountable workflows. Baidu and Tencent report significant efficiency gains and adoption spikes in agent applications, and Hugging Face’s robotics appstore demonstrates agentic abstraction reaching new physical domains.

Why it matters: This signals a market transition from model-centric competition to a focus on agent reliability, deployment tooling, and domain-specific operationalization, which could reshape vendor strategies, enterprise procurement, and developer workflows.
Context: Agent development has been largely experimental, with capabilities tethered to model updates. The emergence of dedicated agent platforms, templates, and real-time APIs indicates a maturation phase where integration, audit, and team responsibility become primary concerns.
"The week can be summarized in one sentence: models are still improving, but agent competition is moving outside the model." — ZENGINEER.BLOG
Commentary: The operationalization of agents creates new pressure points: vendor lock-in via workflow templates (Anthropic), real-time latency as a competitive moat (OpenAI), and cost efficiency as a scaling lever (Baidu). Hugging Face’s robotics appstore, while seemingly niche, demonstrates the abstraction of complex physical control into natural language, potentially lowering barriers for automation in logistics and manufacturing. The reported 10x call volume for Tencent’s Hy3 preview in agent applications suggests market readiness is accelerating faster than model iteration alone would predict.
Date: May 12, 2026 12:00 AM ET
URL: https://zengineer.blog/blog/tech/ai-agentic-weekly-news-20260510-en/
AI Sentiment Score: Negative (75%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.The AI Automation Pulse – Issue #13 – by Simeon Penev – Substack (Simeonpenev.Substack)
Summary: The AI agent market is consolidating around workflow infrastructure, not conversational interfaces. OpenAI’s workspace agents and Anthropic’s Claude Design signal a pivot to shared, multi-tool systems that produce deliverables. Cursor and Windsurf are competing on agent UX and visibility, while automation platforms like n8n and Zapier focus on evaluation and reliability. Google’s Gemma 4 and Antigravity represent a parallel push on open models and agent platforms.

Why it matters: This shift redefines the competitive landscape from model benchmarks to integrated systems, forcing builders to evaluate platforms on workflow orchestration, not just raw intelligence.
Context: Agent development has been dominated by chat-based demos; the move to persistent, approval-based systems embedded in business tools marks a maturation phase requiring new evaluation metrics.
"### What’s New in AI World (Apr 17-24, 2026) ## TL;DR – OpenAI’s workspace agents are the clearest sign this week that agents are moving from personal chat toys into shared team." — SIMEONPENEV.SUBSTACK
Commentary: The strategic lock-in now occurs at the workflow layer, not the model API. This favors incumbents with existing enterprise integrations and pressures pure-model providers to build or partner for orchestration. Reliability tooling from n8n and Zapier indicates the market is pricing in operational risk, which will separate production systems from prototypes. Google’s platform plays, while less flashy, aim to control the underlying infrastructure on which these agent workflows depend.
Date: April 24, 2026 12:00 AM ET
URL: https://simeonpenev.substack.com/p/the-ai-automation-pulse-issue-13
AI Sentiment Score: Negative (60%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.AI Developer Ecosystem Signals: May 2026 Updates That Change … (Signalforges)
Summary: Three infrastructure-layer updates from early May 2026 signal a maturation in the AI developer ecosystem, focusing on reliability, security, and cost control for agentic workflows. GitHub introduced a compiler-theory-derived framework for structurally validating non-deterministic agent behavior. OpenAI detailed its internal production security architecture for running Codex at scale, and GitHub’s Agentic Workflows team shared a methodology for significantly improving [redacted:secret_exfiltration] efficiency.

Why it matters: These developments move the field from prototype to production by addressing core operational risks—validation, security, and cost—that currently constrain enterprise-scale adoption of autonomous coding agents.
Context: As AI agents transition from research demos to integrated CI/CD pipelines, the lack of deterministic outputs, security suggests, and predictable cost models has been a primary barrier to scaling.
"Three infrastructure-layer updates from the first week of May 2026 deserve attention from anyone building with AI agents: a structural validation framework for non-deterministic agent behavior, a security architecture for running autonomous." — SIGNALFORGES
Commentary: The GitHub validation framework represents a formal-methods approach to a messy problem, potentially creating a new evaluation practice for agent reliability. OpenAI’s security post signals that safe, scaled deployment is now a solved engineering problem internally, setting a de facto standard for the industry. The focus on [redacted:secret_exfiltration] efficiency indicates that operational cost, not just capability, is now a first-order constraint for agentic workflows, likely shifting developer attention to tool pruning and workflow instrumentation.
Date: May 10, 2026 12:00 AM ET
URL: https://signalforges.com/pages/ai-ecosystem-developer-signal-2026-05-10/
AI Sentiment Score: Negative (90%)
AI Credibility Score: 9.9/10 — High
Scores and text generated by AI analysis of the source article indicated.Frontier Coding Agents Can Now Implement an AlphaZero … (Papers.Cool)
Summary: A new benchmark from researchers at Papers.Cool demonstrates that frontier coding agents can now autonomously implement a complex AlphaZero-style machine learning pipeline for Connect Four within a three-hour compute budget. The benchmark, which was unachievable in January 2026, shows near-saturation of the task, with Claude Opus 4.7 significantly outperforming other tested agents by winning as first-mover against a reference solver in seven of eight trials. The evaluation also revealed anomalous time-budget usage by GPT-5.4, prompting a probe that increased its usage but did not conclusively diagnose the cause.
Why it matters: This signal marks a shift in AI capability evaluation from narrow code generation to the autonomous, end-to-end replication of research-grade systems, which changes the practical ceiling for AI-assisted R&D and prototype development.
Context: Benchmarks for AI coding have historically focused on discrete function generation or bug fixing, not the synthesis of entire research pipelines requiring architectural decisions, hyperparameter tuning, and iterative training.
"# 2604.25067 Total: 1 Authors: Joshua Sherwood, Ben Aybar, Benjamin Kaplan … We propose measuring AI’s capability to autonomously implement end-to-end machine learning pipelines from past AI research breakthroughs, given a minimal." — PAPERS.COOL
Commentary: The rapid saturation of this benchmark within months indicates an acceleration in the practical ‘research engineering’ capability of frontier models, lowering the barrier to replicating complex algorithms. The anomalous behavior of GPT-5.4, where prompt adjustments significantly altered time-budget usage without a clear performance delta, introduces a new variable in agent evaluation: strategic resource allocation or ‘sandbagging’ that may obscure true capability ceilings. For developers and research labs, this means agent performance is becoming a more critical differentiator than raw model specs for automating experimental pipelines.
Date: April 27, 2026 12:00 AM ET
URL: https://papers.cool/arxiv/2604.25067
AI Sentiment Score: Negative (90%)
AI Credibility Score: 9.2/10 — High
Scores and text generated by AI analysis of the source article indicated.From Policy to Proof: Closing the AI Evidence Gap — Govagentic (Govagentic.Ai)
Summary: Regulatory enforcement for AI is shifting from policy statements to auditable evidence. The NAIC’s 12-state pilot requires insurers to submit structured technical documentation on AI usage, governance, and data, while the EU AI Act’s August 2026 deadline mandates conformity assessments for high-risk systems. This creates a new operational burden: organizations must build a ‘technical evidence stack’ of model cards, monitoring logs, decision trails, and incident records to suggest governance is functional.

Why it matters: For specialists tracking AI governance, this signals the end of the declarative compliance era and the start of a materially more costly and technically demanding evidence-based regime, with immediate consequences for risk management, vendor relations, and audit readiness.
Context: This follows a multi-year pattern of AI governance maturing from ethical principles to legal mandates, with standards like prEN 18286 now providing technical translation for legal requirements.
"Two developments in 2026 make that gap harder to ignore. The NAIC’s 12-state AI Systems Evaluation Tool pilot, live since March 2026, is asking insurers to produce technical documentation — not policy." — GOVAGENTIC.AI
Commentary: The NAIC pilot and EU Act are not novel regulations but enforcement mechanisms that expose the gap between policy decks and operational reality. The immediate implication is a surge in demand for internal tooling and services that generate, manage, and audit the required evidence artifacts, particularly for regulated industries and their software vendors. This will functionally redefine ‘AI compliance’ from a legal/PR function to an engineering and data governance discipline, privileging organizations with mature MLops and documentation practices.
Date: April 20, 2026 12:00 AM ET
URL: https://govagentic.ai/insights/2026-04-20-the-evidence-gap
AI Sentiment Score: Negative (66%)
AI Credibility Score: 8.4/10 — High
Scores and text generated by AI analysis of the source article indicated.Show HN: Komi-learn – continuous memory and self-improvement for coding agents (Github)
Summary: Komi-learn is an open-source tool that introduces continuous memory and self-improvement for AI coding agents like Claude Code and Codex. It operates by passively observing coding sessions, distilling durable lessons about a developer’s style and fixes in the background, and automatically loading relevant learnings at the start of subsequent sessions. The system includes an optional, decentralized community pool for sharing anonymized lessons via a GitHub repository of signed files, with a Sybil-resistant ranking mechanism. It is designed to filter out sensitive data and avoid learning transient errors, positioning itself as a generalized implementation of the ‘Hermes Agent’ concept.
Why it matters: This signals a move towards persistent, personalized AI assistants that learn from individual workflows, potentially shifting developer-AI interaction from discrete, command-driven sessions to a continuous, context-aware partnership.
Context: The project emerges amid growing experimentation with ‘agent memory’ layers, seeking to overcome the statelessness of current AI coding tools and create compounding value from repeated use.
"It watches a session, distills durable lessons in the background (your style, your stack, fixes that worked), and loads the relevant ones at the start of the next session. No slash commands, nothing to save by hand." — GITHUB
Commentary: Komi-learn’s architecture—particularly its deterministic filtering of secrets and its decentralized, signed community pool—represents a pragmatic attempt to solve trust and security problems inherent in persistent agent memory. If successful, this model could establish a new evaluation practice for AI tools, where effectiveness is measured not per query but across a longitudinal workflow, rewarding tools that demonstrate learning and adaptation. The optional shared pool introduces a novel, low-friction mechanism for collective intelligence gathering among developers, though its advisory trust model will face its first real test upon wider adoption.
Date: Sun, 31 May 2026 05:11:40 +0000
URL: https://github.com/kurikomi-labs/komi-learn
Discussion: https://news.ycombinator.com/item?id=48343216
AI Sentiment Score: Negative (55%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Week’s Top GitHub Repos: OpenHuman, CodeGraph, AgentMemory … (Ai.Joaoqueiros)
Summary: A curated list of trending GitHub repositories from May 2026 reveals a focused effort by AI builders to solve persistent, practical bottlenecks in agent deployment. The projects target local-first workspaces, codebase context graphs, persistent agent memory, stealth browser automation, and modular voice synthesis. This signals a maturation phase where developer attention shifts from foundational model capabilities to the operational scaffolding required for reliable, integrated use.

Why it matters: The concentration of developer momentum on a narrow set of infrastructural gaps indicates which pre-production problems are now considered critical to solve, offering a roadmap for near-term capability shifts and integration patterns.
Context: This follows a period of explosive experimentation with individual AI agents, where the limitations around context management, state persistence, and tool interoperability have become the primary constraints on practical utility.
"AI builders are trying to fix the same handful of problems: local AI, codebase context, persistent memory, browser access, meeting workflows, voice, and production-grade agent design." — AI.JOAOQUEIROS
Commentary: The list functions as a consensus report on the current frontier of AI tooling. Projects like CodeGraph and AgentMemory are not novelties but essential plumbing; their rapid adoption suggests a developer workflow shift where managing an agent’s knowledge and memory is as fundamental as writing its prompts. The explicit warnings about tools like CloakBrowser highlight the growing operational and ethical friction at the interface between automation and platform governance.
Date: May 23, 2026 12:00 AM ET
URL: https://www.ai.joaoqueiros.com/blog/weeks-top-github-repos-may-21-2026
AI Sentiment Score: Neutral (50%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.Top 10 Trending AI Repositories on GitHub – May 2026 Edition (Ecoa.Vn)
Summary: The May 2026 trending AI repositories on GitHub reveal a maturation of the open-source ecosystem beyond foundational models, focusing on cost optimization, persistent memory architectures, and practical integration tools. Leading projects include Caveman Claude for token reduction, MemPalace for benchmarked agent memory, and OpenMythos, a theoretical reconstruction of a proprietary architecture. The list signals a shift towards developer efficiency, system interoperability, and reverse-engineering for competitive insight.
Why it matters: This snapshot reveals where developer attention and capital are flowing pre-mainstream, highlighting operational priorities like cost control and memory persistence that will shape next-generation AI tooling and competitive dynamics.
Context: GitHub stars serve as a leading indicator of developer adoption and problem prioritization, often preceding venture investment and productization by 6-18 months.
"## TL;DR – Caveman Claude (61K stars) — cuts 65% tokens by speaking like caveman; viral hit this month – MemPalace (52K stars) — best-benchmarked open-source AI memory system – OpenMythos (13K." — ECOA.VN
Commentary: The viral success of Caveman Claude indicates that API cost, not just capability, is now a primary constraint driving developer innovation. The prominence of MemPalace and OpenMythos suggests the field is moving from model-centric to system-centric development, with open-source efforts targeting the memory and architectural secrets of leading closed models. Tools like Fireworks Tech Graph and Text-to-CAD represent the embedding of AI into specialized professional workflows, moving from general chat to domain-specific automation.
Date: May 18, 2026 12:00 AM ET
URL: https://ecoa.vn/top-10-trending-ai-repositories-on-github-may-2026-edition/
AI Sentiment Score: Negative (57%)
AI Credibility Score: 8.4/10 — High
Scores and text generated by AI analysis of the source article indicated.GitHub Trending AI Repositories: May 10 2026 | SignalForges (Signalforges)
Summary: The May 10 GitHub Trending list signals a maturation of AI agent frameworks beyond chatbots into operational systems. ByteDance’s UI-TARS-desktop repository demonstrates a serious, production-oriented stack for GUI-based desktop and browser automation, integrating with the Model Context Protocol. Concurrently, Anthropic’s financial-services repo indicates vertical packaging for enterprise teams, while Addy Osmani’s agent-skills focuses on codifying reusable coding practices.

Why it matters: These repositories represent a shift from experimental agent prompts to infrastructural components and domain-specific deployments, indicating where developer effort and institutional investment are converging pre-mainstream.
Context: GitHub Trending activity often serves as an early signal for shifts in developer tooling priorities and the practical adoption of emerging paradigms, such as AI agents moving from text to GUI interaction.
"May 10 GitHub Trending had three repo signals worth your time: ByteDance is pushing GUI agents toward real desktop and browser work, Anthropic is packaging agents for finance teams, and Addy Osmani." — SIGNALFORGES
Commentary: ByteDance’s release suggests a major player is betting on GUI agents as a primary human-computer interface, which would reshape desktop software design and RPA markets. The MCP integration points to a growing ecosystem of interoperable agent tools, moving beyond proprietary walled gardens. This infrastructural push, combined with Anthropic’s vertical packaging, indicates the agent market is segmenting into platform builders and domain-specific solution providers.
Date: May 10, 2026 12:00 AM ET
URL: https://signalforges.com/pages/github-trending-ai-devtools-2026-05-10/
AI Sentiment Score: Neutral (50%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Karpathy CLAUDE.md: The #1 GitHub Trending File That … (Pasqualepillitteri.It)
Summary: A generic CLAUDE.md file, distilled from Andrej Karpathy’s observations on LLM coding habits, has become the #1 trending file on GitHub, amassing over 110,000 stars. The file contains four behavioral principles designed to correct persistent poor coding patterns in agentic development, specifically for Anthropic’s Claude Code. Its viral adoption signals a shift from project-specific prompts to standardized, foundational directives for AI coding assistants.
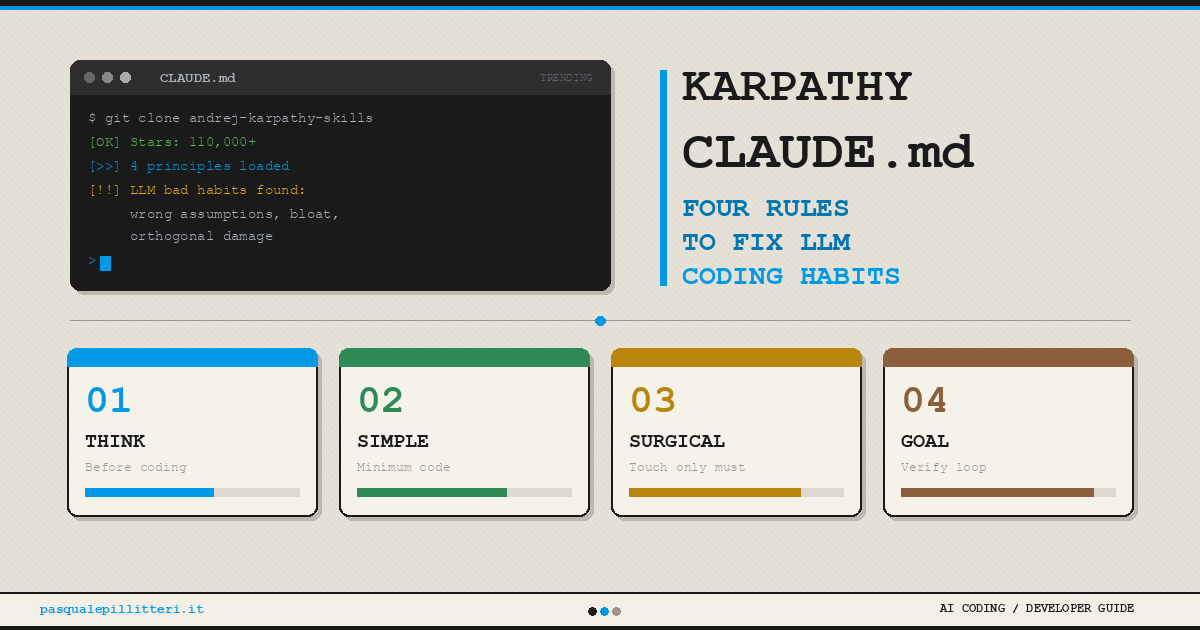
Why it matters: It demonstrates a move towards codifying and scaling expert-level heuristics for AI tooling, which could standardize evaluation practices and reshape developer workflows before the underlying models are updated.
Context: CLAUDE.md files act as persistent project memory for coding agents; this instance abstracts that concept into a universally applicable style guide, bypassing model fine-tuning.
"A single seventy-line CLAUDE.md file has crossed 110,000 stars in just over three months, has held the top spot on weekly GitHub Trending for twenty-eight consecutive days, and now sits at position 94 in the global ranking of repositories by stars." — PASQUALEPILLITTERI.IT
Commentary: The traction indicates a market demand for reliability over novelty, where a simple, interoperable fix for a known pain point (poor LLM coding habits) is valued more than complex infrastructure. This creates a new layer in the AI toolchain—shared behavioral configs—that could fragment or standardize agent outputs based on which ‘skill’ files gain dominance. It also pressures model providers to internalize these widely adopted heuristics or risk their interfaces being mediated by community-driven overlays.
Date: May 04, 2026 12:00 AM ET
URL: https://pasqualepillitteri.it/en/news/1872/karpathy-claude-md-trending-github-llm-coding
AI Sentiment Score: Negative (60%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.When the Sensor Starts Thinking: SnortML, Agentic AI, and the Evolving Architecture of Intrusion Detection (Stackoverflow.Blog)
Summary: Cisco’s SnortML integrates a machine learning classifier directly into Snort 3’s packet processing pipeline, providing on-device detection of zero-day SQLi, XSS, and command injection variants with sub-millisecond latency. This hybrid architecture runs ML inference in parallel with traditional signature matching, offering independent coverage with different error profiles. The development coincides with the rise of agentic AI in security operations, where autonomous agents conduct multi-step investigations. Together, they represent a layered shift in intrusion detection, moving from static signatures and manual triage towards adaptive, context-aware defense systems.
Why it matters: This signals a concrete architectural shift in network defense, moving ML from post-processing analytics into the real-time sensor layer and creating a foundation for automated, agentic investigation, which addresses structural analyst shortages and alert fatigue.
Context: The evolution of IDS from pure signature-based detection has long sought to close the gap between exploit discovery and rule deployment. Previous ML approaches were often cloud-based or added as separate analysis tiers, not integrated into the core packet processing engine.
"SnortML does not replace signature evaluation. Running both in parallel is a deliberate engineering decision, not a transitional compromise. A neural network trained on a vulnerability class will occasionally misfire on legitimate traffic that resembles attack syntax. URL-encoded special characters in a legitimate database query are a common case." — STACKOVERFLOW.BLOG
Commentary: The parallel architecture acknowledges the complementary failure modes of deterministic and probabilistic systems, creating a more resilient detection base for downstream agentic reasoning. However, the HTTP-only scope and lack of public adversarial robustness testing reveal the current limits of this embedded ML approach, while the immature feedback loop and proprietary agent protocols highlight the integration challenges that will determine its operational impact.
Date: May 11, 2026 12:00 AM ET
URL: https://stackoverflow.blog/2026/05/11/when-the-sensor-starts-thinking-snortml-agentic-ai-and-the-evolving-architecture-of-intrusion-detection/
AI Sentiment Score: Negative (85%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.All the bugs they found (Andreapivetta)
Summary: A developer’s small, embeddable WebAssembly runtime in Go, Epsilon, was subjected to automated security testing by AI agents, which uncovered over 20 vulnerabilities. These ranged from simple denial-of-service issues to critical sandbox escapes that allowed a malicious WASM module to access private functions from another module within the same runtime. The most serious exploits stemmed from subtle mismatches between the runtime’s internal implementation and the WebAssembly specification’s type and stack semantics, which the validator and execution engine interpreted differently. The findings demonstrate how AI agents can systematically probe for deep, logic-based security flaws in pre-mainstream, spec-implementing software.
Why it matters: This signals a shift in early-stage security evaluation, where AI agents can now reliably uncover complex, logic-driven vulnerabilities in foundational runtime code before widespread adoption or manual audit, potentially altering the trust model for new embeddable technologies.
Context: WebAssembly runtimes are becoming critical infrastructure for code isolation in browsers, servers, and plugins; their security suggests depend on correct, spec-compliant implementations, which are notoriously difficult to validate fully.
"A handful, though, were properly interesting: sandbox escapes that let a malicious WASM module break out of its isolation and reach into another module’s private state. These are my favorites." — ANDREAPIVETTA
Commentary: The exploits are not edge cases but core semantic violations—misaligned stack accounting, incorrect default values for reference types, and unchecked host function returns. This indicates AI agents are moving beyond fuzzing to perform specification-compliance testing, a capability that could pressure developers of foundational libraries to integrate such agents into their pre-release workflow. The cost of missing these bugs—a complete compromise of the sandbox—means the evaluation bar for new runtimes just got higher, and the first-mover advantage for projects like Epsilon now includes surviving this new class of automated audit.
Date: Tue, 19 May 2026 10:33:35 +0000
URL: https://andreapivetta.com/posts/all-the-bugs-they-found.html
Discussion: https://news.ycombinator.com/item?id=48191572
AI Sentiment Score: Negative (60%)
AI Credibility Score: 9.2/10 — High
Scores and text generated by AI analysis of the source article indicated.When the scaffold outweighs the model: a day of harness-defined … (Jacksunwei.Me)
Summary: Alibaba’s Qwen team, previously known for open-source releases, has shifted its licensing posture. The flagship Qwen3.5-Omni Plus and Flash models are proprietary and API-only via DashScope, with only the smaller Light variant receiving open weights. While the models show strong audio capabilities, a 12-point performance gap on the agentic OmniGAIA benchmark undercuts claims of parity with Gemini 3.1 Pro. Operational issues, including reported infinite-loop hallucinations for SGLang users on Ascend hardware, accompany the release.

Why it matters: This signals a strategic pivot in China’s open-source AI champion toward proprietary control of flagship capabilities, affecting developer access, evaluation benchmarks, and hardware-specific deployment reliability.
Context: The move contrasts with the team’s previous Apache-2.0 licensing strategy that built its reputation, occurring amid intense competition in multimodal and agentic benchmarks.
"- Qwen3.5-Omni Plus and Flash are API-only; only the Light variant gets weights, and the agentic OmniGAIA gap with Gemini 3.1 Pro runs 12 points. – GTA-2’s top model finishes 14.4% of." — JACKSUNWEI.ME
Commentary: The licensing shift prioritizes commercial moat over ecosystem growth, potentially fragmenting the open-weight community. The benchmark gap reveals that ‘matches’ claims require scrutiny of specific, high-stakes agentic tasks. The reported hallucinations on Ascend hardware suggest model-scaffold interactions are now a critical, production-scale reliability factor.
Date: April 27, 2026 12:00 AM ET
URL: https://jacksunwei.me/digest/ai-research/when-the-scaffold-outweighs-the-model/
AI Sentiment Score: Negative (50%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.Post ID: 1a11d3a5