Independent Operator & Newsletter Analysis
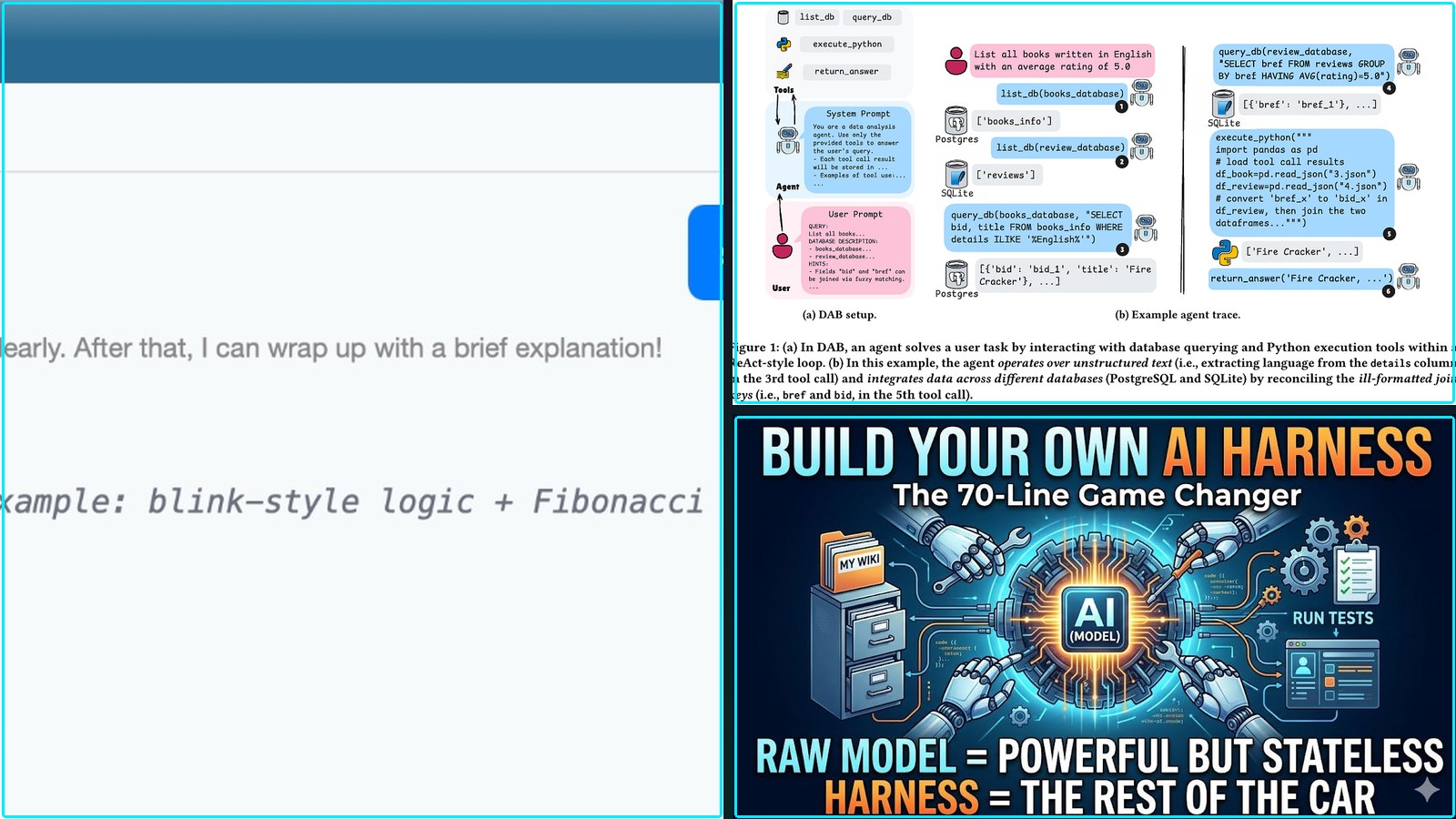
Running Python code in a sandbox with MicroPython and WASM (Simonwillison.Net)
Summary: Simon Willison has released an alpha package, micropython-wasm, which uses a WebAssembly-compiled MicroPython interpreter to create a code execution sandbox for Python applications. The project aims to safely run untrusted plugin code within his Datasette and LLM projects by enforcing memory, CPU, and filesystem limits via the wasmtime engine. This approach addresses a long-standing security gap in his plugin ecosystems, where code currently runs with full host privileges. The implementation allows for persistent interpreter sessions and controlled exposure of host functions, built with significant assistance from AI coding agents.
Why it matters: For independent operators building extensible software, this represents a pragmatic step toward secure, user-contributed functionality without inheriting the maintenance burden or complexity of traditional sandboxing libraries.
Context: Secure sandboxing for dynamic languages in server-side applications remains an unsolved problem, with most existing solutions being brittle, unmaintained, or overly complex. WebAssembly, designed for browser security, is emerging as a viable substrate for server-side isolation.
"WebAssembly is a much better candidate. It was designed from the start to support all of the characteristics I care about and has been tested in browsers for nearly a decade. The wasmtime Python library brings WASM to Python, is actively maintained, and has binary wheels." — SIMONWILLISON.NET
Commentary: Willison’s project is valuable as a field observation and proof-of-concept that shifts the sandboxing conversation from theoretical to operational, using AI-assisted development to navigate low-level C/WebAssembly integration. Its success hinges on whether it can attract security-focused contributors to harden the approach, moving it from a ‘vibe-coded’ alpha to a trusted primitive. This could catalyze a new pattern for safe extensibility in data-centric tools, reducing the barrier for user-generated enrichments and automations.
Date: June 05, 2026 11:53 PM ET
URL: https://simonwillison.net/2026/Jun/6/micropython-in-a-sandbox/
AI Sentiment Score: Negative (50%)
AI Credibility Score: 10.0/10 — High
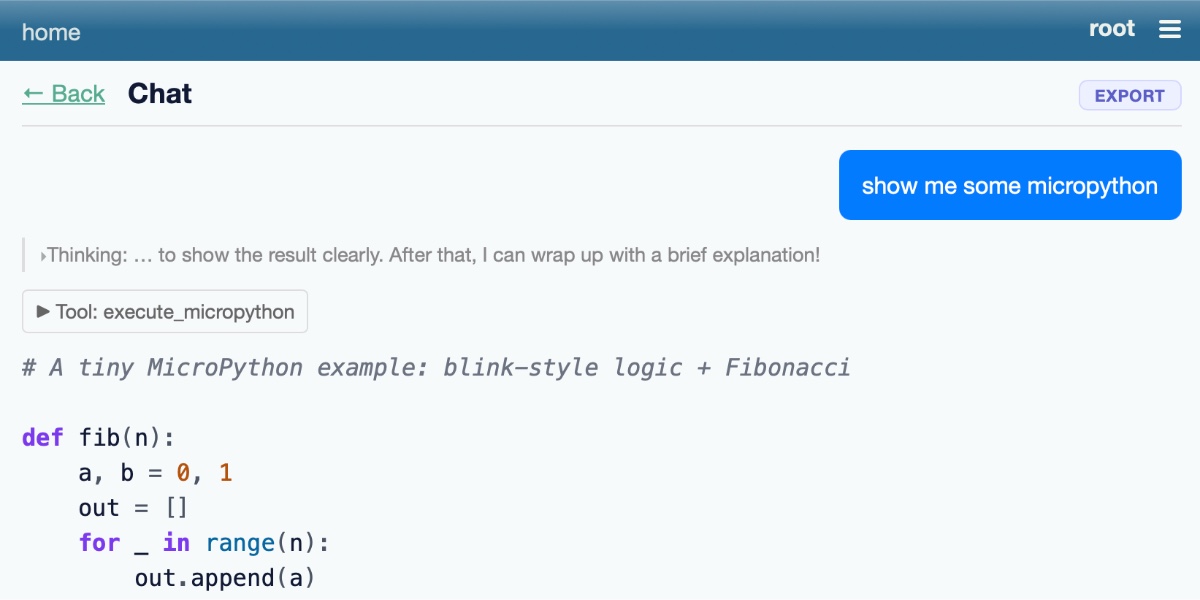
Scores and text generated by AI analysis of the source article indicated.Why AI Data Agents Still Fail at Real Company Data (Medium)
Summary: A new benchmark for AI data agents, DAB, reveals a significant performance gap in real-world business analytics. Testing agents on messy, multi-database queries, the best model achieved only a 38% success rate on its first attempt. Even with 50 retries, the success probability did not exceed 69%, highlighting persistent failures in planning and executing correct analytical procedures over imperfect data.
Why it matters: For independent operators and newsletter analysts, this delineates the practical boundary between AI as a productivity enhancer and a reliable decision-making tool, directly impacting workflows and trust in automated insights.
Context: This follows a wave of hype around AI agents as autonomous analysts, testing them against the complex, multi-source data environments typical of actual business operations rather than clean, single-table demos.
"Why AI Data Agents Still Fail at Real Company Data A new benchmark shows that asking questions in plain English is easy. Getting the right answer from messy business data is still." — MEDIUM
Commentary: The benchmark usefully shifts the focus from linguistic comprehension to analytical integrity, exposing failure modes that mirror human analyst pitfalls—correct data selection followed by flawed computation. This validates a near-term model where agents serve as accelerated assistants, not replacements, demanding verification layers and human oversight for high-stakes conclusions. The competitive edge will belong to systems that prioritize auditability over confidence.
Date: Thu, 04 Jun 2026 08:58:51 GMT
URL: https://medium.com/@davidpupaza3/why-ai-data-agents-still-fail-at-real-company-data-863086d6ac49
AI Sentiment Score: Positive (60%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.I Built My Own AI Harness (and Finally Understood the Tools I Use Every Day) (Javascript.Plainenglish.Io)
Summary: I Built My Own AI Harness (and Finally Understood the Tools I Use Every Day) Let me confess something embarrassing for someone who codes with AI all day. I run Claude Code and Codex every single day. They read my files, run my tests, edit ten things at once, and somehow Just Work.

Why it matters: This matters for Independent Operator & Newsletter Analysis because it gives a concrete current signal to track: I Built My Own AI Harness (and Finally Understood the Tools I Use Every Day) Let me confess something embarrassing for someone who codes with AI all day.
Context: I Built My Own AI Harness (and Finally Understood the Tools I Use Every Day) Let me confess something embarrassing for someone who codes with AI all day. I run Claude Code and Codex every single day. They read my files, run my tests, edit ten things at once, and somehow Just Work.
"I Built My Own AI Harness (and Finally Understood the Tools I Use Every Day) Let me confess something embarrassing for someone who codes with AI all day. I run Claude Code." — JAVASCRIPT.PLAINENGLISH.IO
Commentary: The immediate test is whether this becomes repeatable operator practice rather than another surface-level workflow claim.
Date: Thu, 04 Jun 2026 09:20:04 GMT
URL: https://javascript.plainenglish.io/i-built-my-own-ai-harness-and-finally-understood-the-tools-i-use-every-day-dcebf4449f5a
AI Sentiment Score: Negative (75%)
AI Credibility Score: 8.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Uber Caps Usage of AI Tools Like Claude Code to Manage Costs (Simonwillison.Net)
Summary: Uber has instituted a $1,500 monthly per-tool spending cap for employees using agentic coding software like Claude Code and Cursor, a direct response to blowing its 2026 AI budget within four months. The policy reveals a corporate cost-control mechanism for a new class of unpredictable, high-utility operational expenses. The cap implies an annual AI spend of up to $36,000 per engineer, roughly 11% of the median Uber software engineer’s compensation package.

Why it matters: This marks a shift from experimental AI adoption to a managed corporate utility, establishing a benchmark for the operational cost of AI-augmented engineering and signaling the end of vendor subsidies at scale.
Context: The move follows a pattern of enterprises struggling to forecast and contain costs for generative AI tools, which offer significant productivity gains but with consumption-based pricing that can scale unpredictably.
"3rd June 2026 – Link Blog Uber Caps Usage of AI Tools Like Claude Code to Manage Costs. I wrote the other day about Uber blowing its 2026 AI budget in four." — SIMONWILLISON.NET
Commentary: Uber’s cap is a rational, first-order financial control, but it institutionalizes AI as a line-item cost center rather than an unbounded productivity lever. The 11% of compensation figure provides a rare, concrete valuation of AI’s marginal productivity boost in a real-world enterprise setting. This normalization of quotas could pressure vendors to develop enterprise pricing tiers that decouple cost from raw usage, moving beyond the subsidized individual plans that fueled initial adoption.
Date: June 03, 2026 08:01 AM ET
URL: https://simonwillison.net/2026/Jun/3/uber-caps-usage/
AI Sentiment Score: Negative (75%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Post ID: 25b0dd27