New AI Models, Releases, and Open-Source Developments
Recent open weights model launches (Artificialanalysis.Ai)
Summary: The leading open-weights frontier models from Moonshot AI, Xiaomi, and DeepSeek now score within 3-6 points of top proprietary models on the Artificial Analysis Intelligence Index, a significant narrowing from a 13-point gap a year ago. These are all trillion-plus-parameter MoE models with permissive licenses, offering comparable intelligence at a fraction of the cost. However, substantial performance gaps remain on the hardest reasoning, agentic coding, and knowledge benchmarks, and the top ten open-weights models are all from China-based labs.

Why it matters: The rapid convergence in general benchmarks, coupled with a persistent gap in high-stakes domains, reshapes the competitive and deployment landscape for enterprises and developers weighing cost against capability.
Context: The open-weights ecosystem has historically trailed proprietary leaders, but recent architectural and scaling advances, particularly from Chinese labs, have accelerated performance gains and shifted the cost-to-intelligence Pareto frontier.
"This places the best open weights models within 3-6 points of the leading proprietary models: OpenAI’s GPT-5.5 (xhigh) at 60, and Google’s Gemini 3.1 Pro Preview and AnthropicAI’s Claude Opus 4.7 (Adaptive Reasoning, Max Effort) at 57." — ARTIFICIALANALYSIS.AI
Commentary: The data signals a bifurcation: open weights are now viable for many general applications, but proprietary models retain a decisive edge on frontier tasks like research-level reasoning and reliable agentic coding. This entrenches a two-tier market where cost-sensitive adoption will accelerate, while high-stakes enterprise and research workflows remain locked to closed ecosystems. The geographic concentration of top open models also suggests divergent technological trajectories and supply chain dependencies that will influence global AI policy and procurement.
Date: April 30, 2026 12:00 AM ET
URL: https://artificialanalysis.ai/articles/recent-open-weights-model-launches
AI Sentiment Score: Negative (62%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Last Week In Multimodal AI #54: Open Weights Pulled Even (Thelivingedge.Substack)
Summary: Open-weight multimodal models have reached parity with leading closed models on key benchmarks, with Moonshot AI’s Kimi K2.6 outperforming GPT-5.4 and Claude Opus 4.6 on the HLE-Full with tools benchmark. The release of persistent, editable 3D assets from Tencent HY-World 2.0 and NVIDIA Lyra 2.0 marks a shift from video generation to usable 3D content creation. Simultaneously, agentic coding benchmarks like SWE-Bench are becoming the new competitive frontier, with models like Qwen3.6-35B-A3B achieving high scores under permissive licenses.
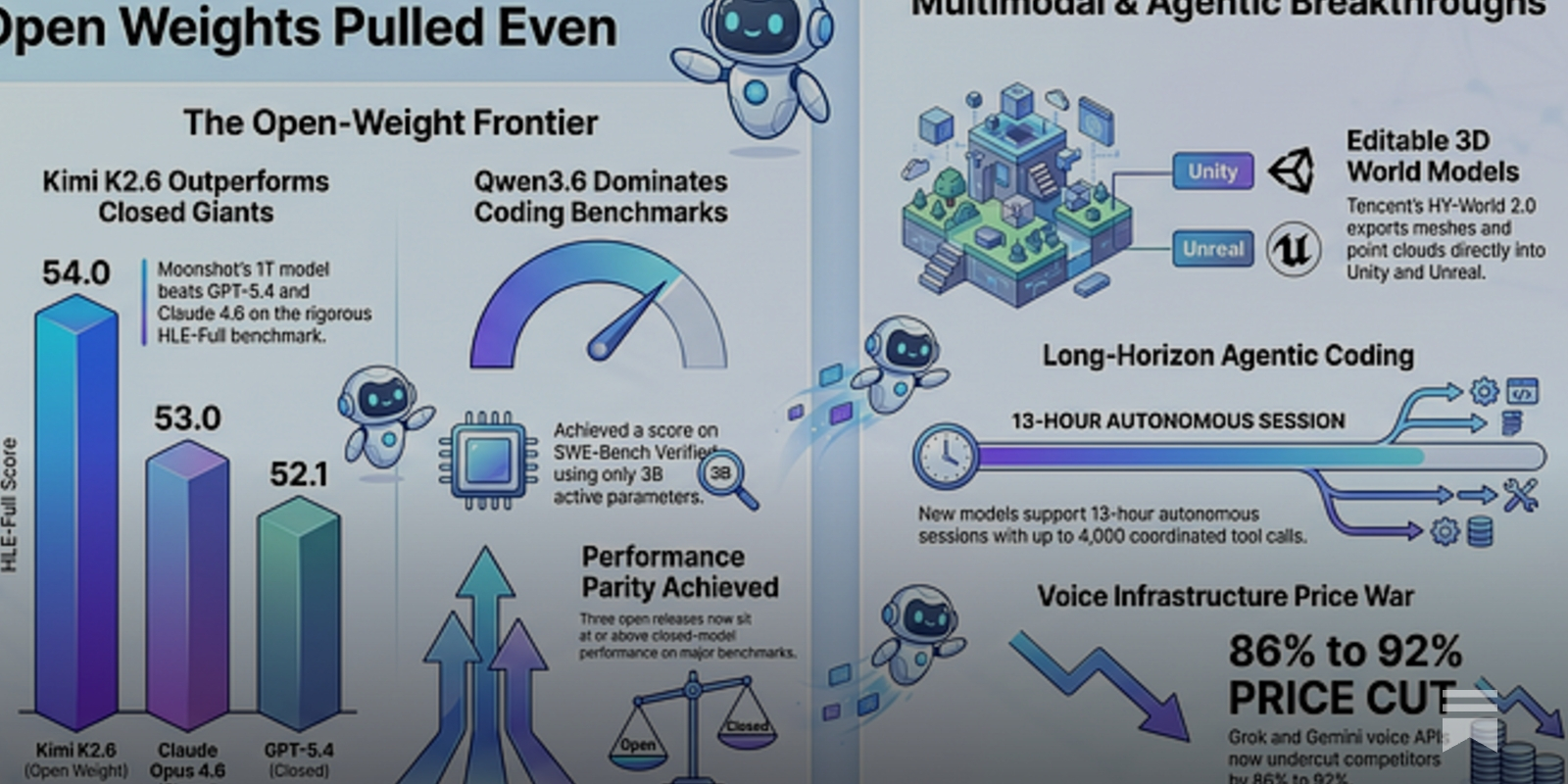
Why it matters: This signals a fundamental shift in the competitive landscape, where open models now offer frontier performance at drastically lower cost, potentially reshaping developer adoption, enterprise procurement, and the economic moats of incumbent AI labs.
Context: The race for multimodal supremacy has been dominated by closed, API-accessed models from OpenAI, Anthropic, and Google. Open-weight releases have historically lagged in performance, particularly on complex, tool-integrated tasks.
"# Last Week In Multimodal AI #54: Open Weights Pulled Even ### Your Weekly Multimodal AI Roundup (Apr 14 to Apr 21, 2026) ## Quick Hits – **Open weights pulled up to." — THELIVINGEDGE.SUBSTACK
Commentary: The benchmark parity, especially on tool-use and coding tasks, erodes the primary justification for vendor lock-in with closed APIs. When combined with Kimi K2.6’s pricing on Cloudflare Workers AI—reportedly 15x cheaper than Claude Opus for heavy workloads—it creates immediate pressure on the unit economics and deployment flexibility of closed model providers. The parallel maturation of 3D world models into editable assets suggests the next wave of commercial competition will be in content pipelines, not just chat interfaces.
Date: April 23, 2026 12:00 AM ET
URL: https://thelivingedge.substack.com/p/last-week-in-multimodal-ai-54-open
AI Sentiment Score: Negative (80%)
AI Credibility Score: 9.2/10 — High
Scores and text generated by AI analysis of the source article indicated.Last Week In Multimodal AI #54: Open Weights Pulled Even (Thelivingedge.Substack)
Summary: Open-weight multimodal models have reached performance parity with leading closed models on key benchmarks, with Kimi K2.6 surpassing GPT-5.4 and Claude Opus 4.6 on the HLE-Full benchmark with tools. Simultaneously, 3D world models like NVIDIA Lyra 2.0 are shifting from generating transient video to producing editable, persistent 3D assets for standard engines. The agentic coding benchmark SWE-Bench has become a primary competitive arena, with models like Qwen3.6-35B-A3B achieving high scores with a fraction of the active parameters.
Why it matters: This marks a structural shift in the AI landscape where open-weight models are no longer lagging indicators but viable, cost-effective alternatives for high-stakes tasks, directly impacting deployment economics and vendor lock-in.
Context: The performance gap between open and closed models has been a persistent feature of the AI market, with frontier capabilities typically reserved for proprietary APIs. Benchmark focus has recently shifted from general knowledge to long-horizon, tool-using tasks like software engineering.
"# Last Week In Multimodal AI #54: Open Weights Pulled Even ### Your Weekly Multimodal AI Roundup (Apr 14 to Apr 21, 2026) ## Quick Hits – **Open weights pulled up to." — THELIVINGEDGE.SUBSTACK
Commentary: The convergence on SWE-Bench signals industry prioritization of autonomous coding as a core economic driver, making benchmark performance a direct proxy for commercial utility. The move from video clips to engine-ready 3D assets by Tencent and NVIDIA indicates a maturation from research demos to pipeline-ready tools, lowering the barrier for content creation at scale. Kimi K2.6’s pricing on Cloudflare Workers AI introduces a 15x cost differential that could pressure closed-model business models, especially for agentic workloads.
Date: April 23, 2026 12:00 AM ET
URL: https://thelivingedge.substack.com/p/last-week-in-multimodal-ai-54-open?triedRedirect=true
AI Sentiment Score: Negative (66%)
AI Credibility Score: 9.2/10 — High
Scores and text generated by AI analysis of the source article indicated.Open-Source Tooling Launches Are Getting More Operational (Insights.Reinventing.Ai)
Summary: Open-source AI agent tooling is shifting from experimental demos to production-ready frameworks focused on operational maintainability. Key projects like LangGraph, OpenAI’s Agents SDK, PydanticAI, and CrewAI are converging on core primitives for durable execution, structured tool calls, human-in-the-loop checkpoints, and built-in observability. The trend enables small teams to implement staged, reliable workflows rather than monolithic autonomous agents. This represents a maturation phase where the bottleneck for SMB and creator adoption is shifting from model capability to operational discipline.

Why it matters: For technical operators, this convergence lowers the integration risk and increases the viability of deploying AI agents in business-critical processes, moving the field from research to operations.
Context: This follows a period of fragmentation in agent frameworks, where novelty often overshadowed reliability, leaving a gap between prototype demos and sustainable deployments.
"The strongest AI agents trend this week is not a single model release. It is the acceleration of open-source agent tooling that makes day-to-day operations easier for small teams. Across major repositories,." — INSIGHTS.REINVENTING.AI
Commentary: The standardization of patterns around durability, tracing, and explicit handoffs indicates a market prioritizing interoperability and risk management over raw autonomy. This creates a foundation for ‘prompt-to-workflow’ packaging, where successful interactions can be formalized into versioned, auditable pipelines, fundamentally changing the cost-benefit analysis for embedding AI in operational workflows.
Date: May 14, 2026 12:00 AM ET
URL: https://insights.reinventing.ai/articles/ai-agents-open-source-tooling-launches-2026-05-14
AI Sentiment Score: Negative (71%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.15 Best AI Models in 2026 for Every Use Case: APIs vs Open Weights (Fluence.Network)
Summary: A 2026 landscape analysis of AI models finds no universal best option, with the market fracturing into specialized tiers: frontier managed APIs for peak quality, high-throughput APIs for volume, and open-weight models for control and portability. Key contenders include GPT-5.4, Gemini 3.1 Pro, Claude Opus 4.6, and Meta’s Muse Spark in the API tier, while open-weight leaders like Qwen3.5-397B-A17B and Llama 4 Scout emphasize deployability, multimodal capability, and long-context experimentation. The piece stresses that long-context claims require independent validation for production reliability and advocates for a three-model evaluation strategy (frontier, workhorse, open-weight) based on real workload metrics.

Why it matters: For technical architects and product leaders, the shift from a monolithic ‘best model’ race to a workload-specific ecosystem changes procurement, system design, and competitive moats, making infrastructure and model portability first-class strategic concerns.
Context: This reflects the maturation of the AI stack beyond raw benchmark scores into a pragmatic, multi-vendor environment where openness, operational cost, and specific capability alignment determine real-world advantage.
"Open-weight models are the right choice when you need control: weights access, fine-tuning, private inference, or the ability to move workloads across providers." — FLUENCE.NETWORK
Commentary: The explicit framing of open-weight models as a control and portability lever, rather than just a cost play, signals a hardening enterprise preference for architectural optionality against vendor lock-in. This could pressure API providers to justify their premium with uniquely sticky workflows or orchestration layers, while accelerating investment in open-model tooling and GPU-cloud interoperability standards.
Date: April 21, 2026 12:00 AM ET
URL: https://www.fluence.network/blog/best-ai-models/
AI Sentiment Score: Negative (57%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.AI Models Released in May 2026: Complete Roundup – Codersera (Codersera)
Summary: Quick answer. May 2026 was dominated by Alibaba (Qwen 3.7-Max preview, May 20), DeepSeek (V4-Pro 75% discount made permanent on May 22 at $0.435/$0.87 per 1M tokens), Google (Gemini 3.5 Flash, May 19), Cursor (Composer 2.5, May 18) and xAI (Grok Build CLI beta, May 14). Anthropic announced a major billing split for June 15 but shipped no new model. Claude Sonnet 4.8, GPT-5.6 and Llama 5 remain unannounced or unreleased.

Why it matters: This matters for Emerging Tech Signals (Pre-Mainstream) because it gives a concrete current signal to track: Quick answer. May 2026 was dominated by Alibaba (Qwen 3.7-Max preview, May 20), DeepSeek (V4-Pro 75% discount made permanent on May 22 at $0.435/$0.87 per 1M tokens), Google (Gemini 3.5 Flash, May 19), Cursor (Composer 2.5, May 18) and xAI (Grok Build CLI beta, May 14).
Context: Quick answer. May 2026 was dominated by Alibaba (Qwen 3.7-Max preview, May 20), DeepSeek (V4-Pro 75% discount made permanent on May 22 at $0.435/$0.87 per 1M tokens), Google (Gemini 3.5 Flash, May 19), Cursor (Composer 2.5, May 18) and xAI (Grok Build CLI beta, May 14). Anthropic announced a major billing split for June 15 but shipped no new model. Claude Sonnet 4.8, GPT-5.6 and Llama 5 remain unannounced or unreleased.
"Quick answer. May 2026 was dominated by Alibaba (Qwen 3.7-Max preview, May 20), DeepSeek (V4-Pro 75% discount made permanent on May 22 at $0.435/$0.87 per 1M tokens), Google (Gemini 3.5 Flash, May." — CODERSERA
Commentary: The immediate implication is operational rather than speculative: watch how this changes budgets, workflows, or risk assumptions over the next cycle.
Date: May 23, 2026 12:00 AM ET
URL: https://codersera.com/blog/ai-models-released-may-2026-monthly-roundup/
AI Sentiment Score: Negative (66%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.New AI Models May 2026: The Frontier Took a Breath … (Whatllm)
Summary: The May 2026 model release cycle shows a market shift toward optimization and architectural experimentation over raw scale. OpenAI’s new ChatGPT default, GPT-5.5 Instant, signals a prioritization of latency and cost, while Subquadratic’s first commercial ‘subquadratic’ LLM and Zyphra’s open-source 8B MoE trained on AMD hardware indicate serious exploration of alternative compute and attention paradigms. The frontier narrative is temporarily sidelined by practical deployment and efficiency concerns.
Why it matters: This consolidation phase redefines competitive moats from pure performance to cost, latency, and architectural flexibility, directly impacting infrastructure decisions and developer toolchains.
Context: The post-GPT-5 era has been characterized by a search for sustainable scaling laws and cost-effective inference, making niche architectural bets and open-weight models increasingly relevant to the operational baseline.
"The interesting story moved sideways, into a new attention architecture, an 8B MoE trained on AMD, and a quieter default in ChatGPT." — WHATLLM
Commentary: OpenAI’s choice of a ‘quieter default’ is a tacit admission that consumer-facing AI has hit a sufficiency threshold, shifting competition to backend economics. Subquadratic’s commercial release validates a previously academic attention method, potentially altering the long-context cost curve. Zyphra’s Apache 2.0 MoE, explicitly trained on AMD, is a direct challenge to NVIDIA’s full-stack dominance, offering a viable open-source path for cost-conscious deployments.
Date: May 13, 2026 12:00 AM ET
URL: https://whatllm.org/blog/new-ai-models-may-2026
AI Sentiment Score: Negative (77%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.Open-Source AI Models 2026: The Creator Reference Guide (Creativeainews)
Summary: A 2026 reference guide for creators details a mature open-source AI ecosystem where production-ready models across modalities are available under permissive licenses. Key signals include DeepSeek V4 offering a 1M-context MoE model under MIT, the proliferation of Apache-licensed video generators like Wan 2.7, and the emergence of unified multi-modal models like Qwen3.5-Omni. The guide emphasizes that all listed models are shipped and have been used in production work within the last 90 days.

Why it matters: For specialists tracking pre-mainstream signals, this snapshot reveals a decisive shift where open-source models are not just research artifacts but are defining the commercial and creative toolchain, with licensing and hardware compatibility becoming primary selection criteria over raw benchmark scores.
Context: This follows years of tension between proprietary frontier models and open-source alternatives, where licensing restrictions often limited commercial deployment. The 2026 landscape suggests open weights have achieved parity or superiority in specific, practical domains like long-context reasoning and real-time video generation.
"DeepSeek V4 shipped a 1M-context, MoE-based open-weights model under MIT license in 2026." — CREATIVEAINEWS
Commentary: The MIT license on a frontier-scale model like DeepSeek V4 is a market-maker, removing legal friction for integration and derivative works. Combined with Apache-licensed video models and llama.cpp’s multi-modal local inference, this signals the operationalization of open-source AI, where developer workflow and cost curve advantages are now concrete rather than aspirational. The focus on ‘used in production’ and commercial verification shifts evaluation practice from academic benchmarks to real-world reliability and interoperability.
Date: April 28, 2026 12:00 AM ET
URL: https://www.creativeainews.com/articles/open-source-ai-models-2026-reference/
AI Sentiment Score: Negative (60%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.New Open-Source AI Projects & Model Releases: May 2026 Roundup (Devflokers)
Summary: The May 2026 open-source AI landscape is defined by a decisive shift toward ‘agentic execution,’ with projects enabling local, private, and autonomous action gaining unprecedented traction. OpenClaw, a personal AI assistant that runs locally and writes its own skills, has become the fastest-growing project in GitHub history, surpassing 302,000 stars. Infrastructure projects like Ollama and Open WebUI continue to underpin the movement, while proprietary model releases from OpenAI, xAI, and Google focus on incremental improvements in reasoning and context. The trending repositories list is dominated by coding and personal agents, signaling developer prioritization of autonomous, integrated workflows over raw model capability.
Why it matters: The velocity and direction of open-source momentum prefigure mainstream adoption patterns, revealing which architectural bets (local execution, skill-writing agents) are gaining developer consensus before enterprise or consumer markets fully react.
Context: The trend follows years of tension between proprietary cloud APIs and open-source inference, with the latter now maturing beyond model access into full-stack, autonomous application frameworks.
"|Model Name|Release Date|Developer|License|Key Innovation| |–|–|–|–|–| |GPT-5.5 Instant|May 5, 2026|OpenAI|Proprietary|50% lower hallucination on free tier| |SubQ 1M-Preview|May 5, 2026|Subquadratic|Proprietary (API)|12M native context window; non-transformer| |Grok 4.3|May 6, 2026|xAI|Proprietary|Advanced reasoning and real-time X data|." — DEVFLOKERS
Commentary: OpenClaw’s growth signals a maturing phase where the value proposition shifts from model access to agentic utility, privileging projects that solve integration and autonomy. The concurrent rise of typed tool plugin frameworks (like defineToolPlugin) indicates a move toward standardized, extensible agent ecosystems, which could commoditize certain API-based services. This creates pressure on proprietary vendors to move up the stack into orchestration and security, as their core inference advantage erodes against locally executable, skill-adaptive agents.
Date: May 19, 2026 12:00 AM ET
URL: https://www.devflokers.com/blog/open-source-ai-projects-may-2026-roundup
AI Sentiment Score: Positive (57%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Last Week in AI #340 – OpenAI vs Musk + Microsoft, DeepSeek v4, Vision Banana (Lastweekin.Ai)
Summary: The first week of the Musk v. Altman trial concluded with Elon Musk’s testimony, centering on claims that OpenAI’s leadership betrayed its nonprofit mission. In parallel, OpenAI restructured its partnership with Microsoft, ending exclusivity and clearing the way for its models to run on AWS. DeepSeek previewed its V4 model series, claiming performance approaching frontier models, while Google DeepMind introduced Vision Banana, a unified model for both image generation and advanced visual understanding tasks.
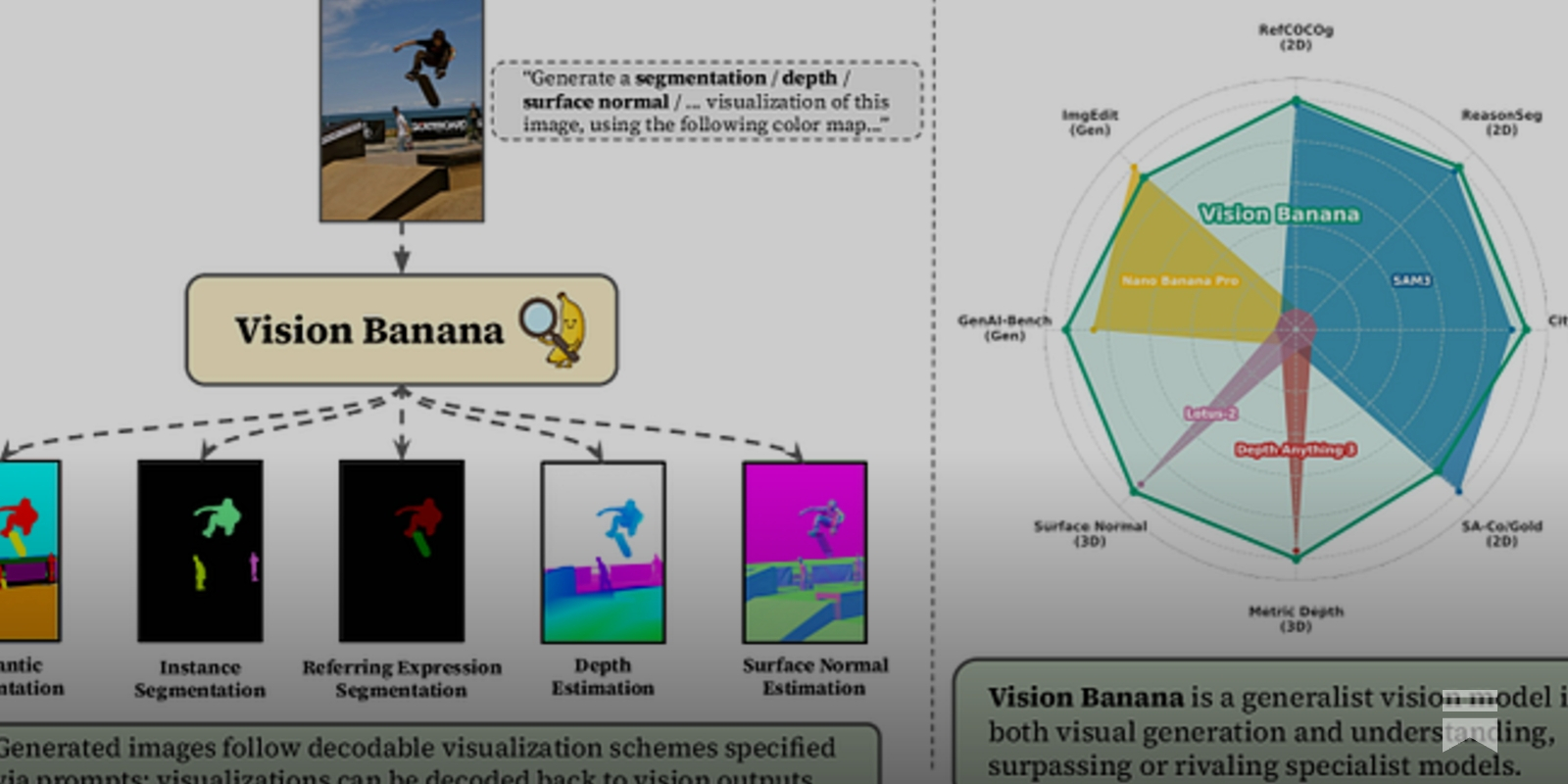
Why it matters: These developments signal critical shifts in AI governance, market structure, and technical capability, directly impacting competitive dynamics, developer access, and the legal frameworks shaping the industry.
Context: The trial exposes the foundational tensions between open, nonprofit AI development and commercial scale. The cloud partnership renegotiation reflects the end of an era of single-vendor exclusivity for frontier AI. DeepSeek’s release continues the pressure on Western frontier models from efficient, open-weight competitors.
"Last Week in AI #340 – OpenAI vs Musk + Microsoft, DeepSeek v4, Vision Banana First week of Musk v. Altman, OpenAI ends Microsoft legal peril over its $50B Amazon deal, DeepSeek." — LASTWEEKIN.AI
Commentary: Musk’s admission undercuts the moral purity of his ‘stolen charity’ argument and normalizes model distillation as a standard industry tactic. The Microsoft-OpenAI deal formalizes the multi-cloud reality, reducing strategic leverage for any single infrastructure provider. Vision Banana’s performance suggests a consolidation path for computer vision, where generative pretraining obviates specialized architectures—a direct parallel to the LLM scaling thesis.
Date: Tue, 05 May 2026 08:30:35 GMT
URL: https://lastweekin.ai/p/last-week-in-ai-340-openai-vs-musk
AI Sentiment Score: Negative (71%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.LWiAI Podcast #242 – ChatGPT Images 2.0, Qwen 3.6 Max, Kimi-K2.6 (Lastweekin.Ai)
Summary: The latest AI development cycle shows a pivot toward specialized, high-fidelity generation and agentic application. OpenAI’s new image model emphasizes precise text rendering, aligning with ‘computer use’ workflows, while Chinese labs accelerate with large, open MoE models like Kimi-K2.6. Concurrently, infrastructure and policy shifts intensify, marked by Cerebras’s IPO filing, Amazon’s $5B Anthropic investment, and emerging concerns over tool access and synthetic media.

Why it matters: These signals indicate a maturation phase where model capability, commercial alignment, and operational security are becoming primary competitive vectors, moving beyond raw scaling.
Context: The trend moves from general-purpose LLMs to models optimized for specific fidelity (text-in-images) or scale-efficiency (MoE), coupled with capital consolidation around a few infrastructure and model providers.
"Note from Andrey: I know there haven’t been posts on Substack in the past couple of weeks… Starting this week they’ll resume at a regular cadence, as usual I apologize for the." — LASTWEEKIN.AI
Commentary: ChatGPT Images 2.0’s text accuracy is not merely an aesthetic improvement; it directly enables reliable automated document and interface generation, reducing the need for post-processing. This, alongside Kimi-K2.6’s 1T-parameter MoE architecture, signals a bifurcation: Western labs may prioritize tight integration into agentic stacks, while Chinese counterparts compete on open, massive-scale efficiency. The reported NSA use of Anthropic’s Mythos, despite a blacklist, underscores that advanced AI tools are already embedded in high-stakes operational environments, rendering purely declarative safety policies ineffective.
Date: Thu, 30 Apr 2026 07:14:45 GMT
URL: https://lastweekin.ai/p/lwiai-podcast-242-chatgpt-images
AI Sentiment Score: Positive (66%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Gemini 3.5: frontier intelligence with action (Deepmind.Google)
Summary: Google DeepMind has launched Gemini 3.5 Flash, positioning it as a frontier intelligence model optimized for agentic tasks and coding. It claims to outperform its predecessor, Gemini 3.1 Pro, on specific benchmarks like Terminal-Bench 2.1 and GDPval-AA while being four times faster in output tokens per second than other frontier models. The model is integrated into Google’s Antigravity development platform and is immediately available via the Gemini API, Google AI Studio, and consumer products like the Gemini app and AI Mode in Search. Enterprise partners, including Shopify, Macquarie Bank, and Salesforce, are cited as early adopters for automating complex, multi-step workflows.

Why it matters: This release accelerates the practical deployment of AI agents by lowering the latency and cost barriers for complex, long-horizon tasks, shifting competition from raw capability to operational efficiency and integration.
Context: The launch follows a pattern of model families bifurcating into ‘fast’ and ‘capable’ tiers, but here the claim is that the speed-optimized tier now achieves ‘frontier’ performance on agentic benchmarks, a significant compression of the traditional trade-off.
"3.5 Flash delivers frontier-level intelligence at exceptional speed — proving you no longer have to trade quality for latency." — DEEPMIND.GOOGLE
Commentary: The operational claim—frontier intelligence without a latency penalty—directly targets the core economic constraint for deploying agents at scale. If substantiated, it pressures competitors to match this efficiency or cede the high-throughput automation market. The deep integration with Antigravity for subagent orchestration and the named enterprise pilots suggest Google is prioritizing a platform lock-in strategy, making the model’s utility contingent on its proprietary toolchain.
Date: Fri, 15 May 2026 22:50:12 +0000
URL: https://deepmind.google/blog/gemini-3-5-frontier-intelligence-with-action/
AI Sentiment Score: Negative (50%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.GPT-5.5 Is ChatGPT’s New Default, Claude Mythos Hunts … (Lablab.Ai)
Summary: OpenAI has made GPT-5.5 Instant the default ChatGPT model, emphasizing reduced hallucinations and shorter, cheaper outputs. Concurrently, Anthropic’s Claude Mythos preview autonomously discovered and exploited thousands of unpatched zero-day vulnerabilities across major OSes and browsers. Meanwhile, Chinese open-weight coding models like Kimi K2.6 now outperform Western frontier models on key benchmarks at a fraction of the inference cost.

Why it matters: The convergence of a cheaper, more accurate default model, a leap in autonomous offensive security capability, and a decisive shift in open-source model competitiveness redefines the practical landscape for developers, security teams, and enterprise procurement.
Context: This accelerates three existing trends: the normalization of rapid, silent model upgrades in consumer-facing AI; the arms race between AI-powered offensive and defensive security tooling; and the erosion of Western frontier model dominance in specialized, cost-sensitive domains like code generation.
"The week split in two directions at once. On one side, the model release cadence kept accelerating: OpenAI shipped a smarter ChatGPT default, and four Chinese labs dropped open-weight coding models that." — LABLAB.AI
Commentary: The Mythos capability shifts vulnerability discovery from a scarce, expert-led process to a scalable, automated one, collapsing the timeline for weaponization and forcing a structural rethink of patch management. The Chinese model benchmarks signal that cost-per-token, not just peak performance, is now the decisive competitive axis for applied AI, likely triggering a wave of re-benchmarking and re-platforming in enterprise dev shops. OpenAI’s silent default switch and tuned cyber variant reveal a strategy of embedding capability while managing ecosystem disruption, making model choice an operational rather than a strategic decision for most API consumers.
Date: May 12, 2026 12:00 AM ET
URL: https://lablab.ai/ai-articles/this-week-in-ai-2026-05-12
AI Sentiment Score: Negative (88%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.LWiAI Podcast #245 – TML-Interaction, Claude For Legal, Sam Altman on Stand (Lastweekin.Ai)
Summary: The latest industry podcast highlights a week of platform-level API expansions and vertical product pushes. OpenAI released new low-latency voice intelligence features powered by GPT-5, while Thinking Machines previewed a proprietary full-duplex conversational system. Anthropic launched Claude for Legal and deepened its AWS integration, signaling intensified competition between foundational model providers and application-layer companies. Concurrently, internal research updates reveal ongoing work on safety guardrails, agent alignment, and the limits of current evaluation benchmarks.
Why it matters: The bundling of advanced real-time capabilities into APIs accelerates the commoditization of conversational AI, while vertical product launches by major labs directly threaten incumbent SaaS vendors and reshape industry power dynamics.
Context: This follows a persistent trend of model providers (OpenAI, Anthropic) expanding downstream into high-margin vertical applications, creating tension with their own developer ecosystem and traditional enterprise software vendors.
"Anthropic pushed further into vertical products with Claude for Legal and deeper AWS availability, while ongoing ecosystem tension grows as platform model providers compete with application-layer companies." — LASTWEEKIN.AI
Commentary: The launch of Claude for Legal is a direct shot across the bow of legal tech incumbents like Thomson Reuters and LexisNexis, demonstrating model providers’ willingness to capture vertical value. Meanwhile, OpenAI’s real-time API and Thinking Machines’ proprietary stack highlight a race to own the latency and interactivity layer, which could become a key differentiator for immersive applications. The reported research on ‘teaching Claude why’ and accidental chain-of-thought grading underscores that frontier labs are still grappling with fundamental control problems even as they commercialize aggressively.
Date: Wed, 20 May 2026 07:45:49 GMT
URL: https://lastweekin.ai/p/lwiai-podcast-245-tml-interaction
AI Sentiment Score: Negative (60%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Gemini for Science: AI experiments and tools for a new era of discovery (Deepmind.Google)
Summary: Google DeepMind has launched Gemini for Science, a suite of experimental AI tools aimed at accelerating research. The initiative includes three primary prototypes: Hypothesis Generation for ideation, Computational Discovery for parallel code testing, and Literature Insights for synthesizing papers. It is complemented by enterprise deployments with partners like BASF and Daiichi Sankyo, and a ‘Science Skills’ bundle integrating biological databases for faster analysis. The effort is framed as a shift toward generalist AI agents to overcome information overload and computational bottlenecks in science.

Why it matters: This signals a strategic push to productize agentic AI for the scientific method itself, moving beyond specialized models to integrated platforms that could reshape research workflows, funding, and competitive advantage in industrial R&D.
Context: This follows DeepMind’s established pattern of transitioning research breakthroughs (AlphaFold, AlphaGenome) into broader toolkits, now under the Gemini brand. The focus on multi-agent ‘idea tournaments’ and parallel computational testing reflects an industry trend toward automating higher-order research functions, not just data analysis.
"Scientific breakthroughs often rely upon making creative connections between data, but the time required to do this manually can take weeks or even months. AI can help eliminate this bottleneck and serve as a force multiplier for scientific work by handling complex tasks." — DEEPMIND.GOOGLE
Commentary: The operational shift here is from AI as a data processor to AI as a co-investigator, automating hypothesis generation and experimental design. If the validation holds, this could compress discovery cycles in fields like materials science and drug development, but it also raises questions about intellectual provenance and the risk of homogenizing scientific creativity. The enterprise previews with BASF and Klarna indicate the immediate commercial target is optimizing industrial R&D pipelines, not just academic curiosity.
Date: Sun, 17 May 2026 13:50:34 +0000
URL: https://deepmind.google/blog/gemini-for-science-ai-experiments-and-tools-for-a-new-era-of-discovery/
AI Sentiment Score: Negative (50%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Fine-Tuning NVIDIA Cosmos Predict 2.5 with LoRA/DoRA for Robot Video Generation (Huggingface.Co)
Summary: NVIDIA’s Cosmos Predict 2.5, a 2B-parameter world model for video generation, can now be efficiently fine-tuned for specific domains like robot manipulation using LoRA and DoRA adapters. A new guide details the process, enabling adaptation on a single GPU and demonstrating significant improvements in task-specific generation for synthetic robot training data. The work shows that a rank-8 LoRA adapter, trained for 100 epochs, is sufficient to correct major out-of-distribution failures like hallucinated human hands and incorrect limb usage, while higher ranks improve instruction following. The practical result is a method to generate geometrically consistent, physically plausible robot demonstration videos at scale, reducing reliance on expensive real-world data collection.

Why it matters: It lowers the cost and expertise barrier for specializing large world models to niche industrial applications, making synthetic data generation a viable, scalable alternative to physical data collection for robotics.
Context: Parameter-efficient fine-tuning (PEFT) methods like LoRA are becoming standard for adapting large generative models, but their application to billion-parameter video diffusion models for precise, physics-aware tasks like robotic manipulation is a newer frontier with high-stakes implications for simulation and training.
"Before fine-tuning, the base model struggles in several ways: robot hands are out-of-distribution, causing the model to hallucinate human hands in later frames; it does not reliably use the correct hand specified in the prompt; and the generated videos exhibit noticeable jitter. Fine-tuning with LoRA and DoRA addresses all three issues." — HUGGINGFACE.CO
Commentary: The signal is the operationalization of a previously theoretical capability: cheap, targeted adaptation of a massive world model to a narrow, high-fidelity domain. The implication is that the bottleneck for synthetic data shifts from model scale to dataset curation and adapter training workflows. This creates a new evaluation axis for world models—not just raw capability, but their ‘PEFT-ability’ for industrial use cases. Institutions building internal simulation stacks must now factor adapter management and versioning into their infrastructure.
Date: Mon, 18 May 2026 16:00:21 GMT
URL: https://huggingface.co/blog/nvidia/cosmos-fine-tuning-for-robot-video-generation
AI Sentiment Score: Positive (42%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.PopuLoRA: Co-Evolving LLM Populations for Reasoning Self- Play (Vmax.Ai)
Summary: Researchers from Vmax.Ai propose PopuLoRA, a method for training co-evolving populations of LLM adapters to generate their own adaptive curriculum for reinforcement learning with verifiable rewards (RLVR). The system separates ‘teacher’ models that generate code-based tasks from ‘student’ models that solve them, with teachers rewarded for creating valid tasks that their matched student fails to solve. This prevents the curriculum collapse observed in single-agent self-play, where models generate only tasks they can already solve, and instead drives the generation of increasingly complex and diverse programs. The approach, made computationally feasible by using LoRA adapters on a frozen base model and online weight-space evolution, shows improved performance on code and math reasoning benchmarks.
Why it matters: It demonstrates a practical, scalable method to move beyond fixed, hand-curated datasets for RLVR, enabling models to autonomously generate a self-improving training frontier, which is a core challenge for advancing reasoning capabilities.
Context: Current RLVR systems often rely on static, pre-defined task distributions, which can limit progress as models outgrow them. Self-play offers an adaptive alternative but has struggled with curriculum collapse, where a model’s task generation converges on problems it already masters.
"In practice, we find that single-agent self-play self-calibrates: task generation converges toward valid tasks that its own solver can already handle, solve rate climbs toward 100%, and the curriculum collapses onto increasingly simple programs. The reward curve looks healthy, but the training distribution has stopped pushing the model." — VMAX.AI
Commentary: PopuLoRA’s core innovation is reframing difficulty from a self-referential metric to an inter-population signal, creating a sustainable arms race. The technical implementation—using LoRA for affordability and weight-space evolution for diversity—makes population-based training operationally viable on a single machine, lowering the barrier to experimentation. This shifts the research focus from designing better static curricula to engineering systems that can co-evolve their own challenges, a necessary step for models that must improve beyond human-specified benchmarks.
Date: Wed, 20 May 2026 21:11:55 +0000
URL: https://vmax.ai/team/populora-co-evolving-llm-populations-for-reasoning-self-play
Discussion: https://news.ycombinator.com/item?id=48214188
AI Sentiment Score: Negative (63%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Recent Developments in LLM Architectures: KV Sharing, mHC, and Compressed Attention (Magazine.Sebastianraschka)
Summary: Recent open-weight LLM releases from Google, Poolside, Zyphra, and DeepSeek are converging on a shared architectural goal: drastically reducing the cost of long-context inference. Techniques like KV sharing (Gemma 4), layer-wise attention budgeting (Laguna XS.2), compressed convolutional attention (ZAYA1-8B), and hybrid compressed attention with manifold-constrained hyper-connections (DeepSeek V4) represent targeted, pre-production tweaks to the transformer block. The focus has shifted from merely scaling parameter counts to optimizing memory traffic, KV cache size, and attention FLOPs for sequences exceeding 100k tokens.

Why it matters: These architectural shifts directly impact the economics and feasibility of deploying reasoning models and persistent agents, moving long-context capability from a benchmark novelty to a practical, operational concern.
Context: This follows a broader industry trend where KV cache size and memory bandwidth, not just FLOPs, have become the primary bottlenecks for long-context workloads, prompting a wave of specialized attention variants and cache compression schemes.
"Recent Developments in LLM Architectures: KV Sharing, mHC, and Compressed Attention From Gemma 4 to DeepSeek V4, How New Open-Weight LLMs Are Reducing Long-Context Costs After a short family break, I am." — MAGAZINE.SEBASTIANRASCHKA
Commentary: The proliferation of these techniques signals a maturation phase where architectural innovation is driven by deployment constraints rather than pure scaling laws. However, it introduces significant implementation complexity and risks fragmenting the optimization landscape, as each lab’s proprietary compression scheme may yield diminishing returns on interoperability and evaluation clarity. The real test will be whether these efficiency gains translate to reliable performance in agentic loops, not just retrieval benchmarks.
Date: Sat, 16 May 2026 11:33:51 GMT
URL: https://magazine.sebastianraschka.com/p/recent-developments-in-llm-architectures
AI Sentiment Score: Negative (75%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.My Workflow for Understanding LLM Architectures (Magazine.Sebastianraschka)
Summary: Sebastian Raschka details his manual workflow for reverse-engineering the architectures of open-weight large language models, moving beyond often-sparse official papers to directly inspect configuration files and reference implementations. This process, reliant on model availability on platforms like Hugging Face, is framed as a learning exercise to produce accurate architectural diagrams. It highlights a growing information asymmetry between open and closed models.
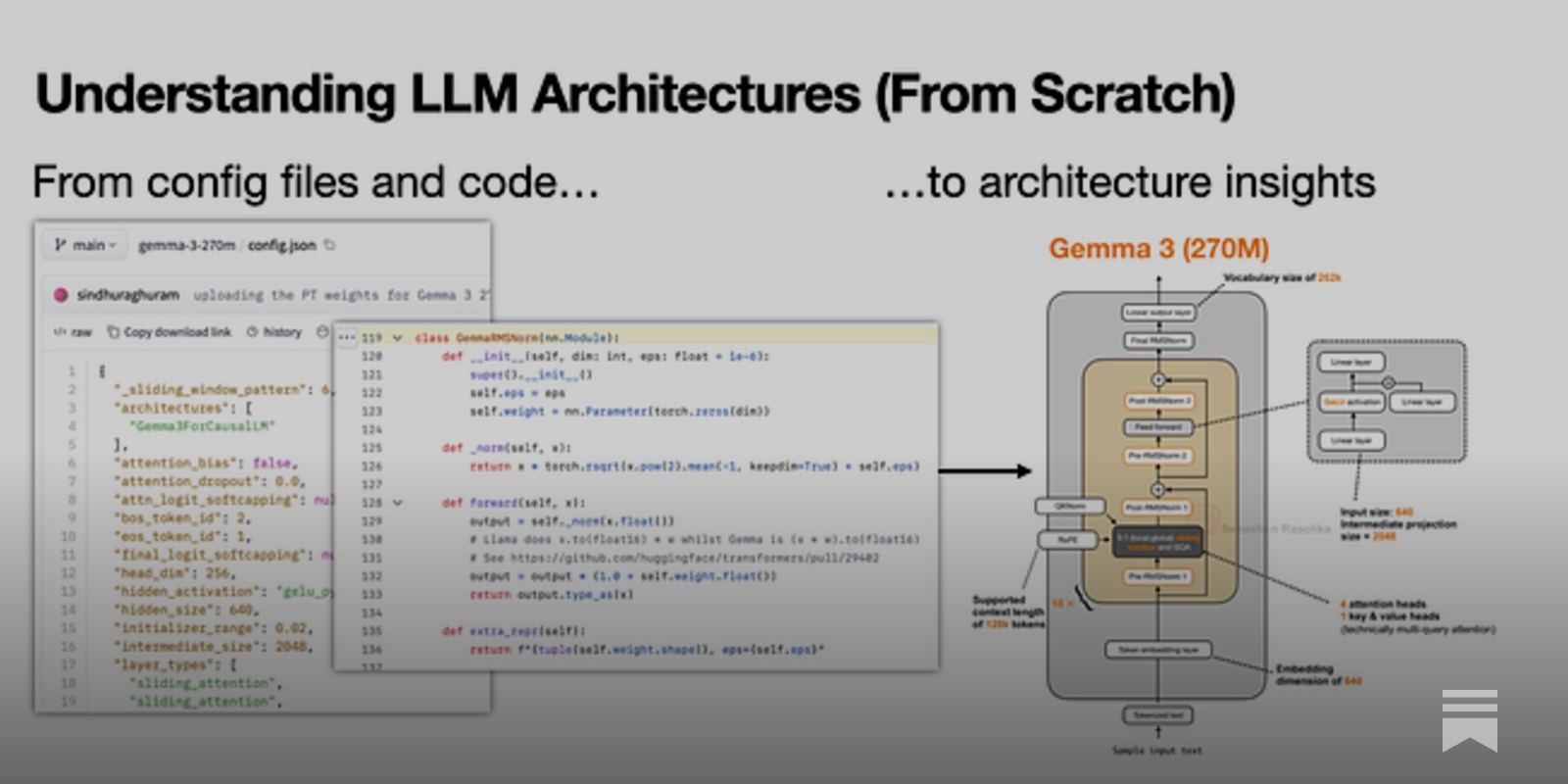
Why it matters: It codifies a critical methodology for independent technical analysis in an era where model documentation is increasingly incomplete, establishing a baseline for rigorous, pre-consensus understanding.
Context: Technical reports for new models, especially from industry labs releasing open weights, have become less detailed, shifting the burden of architectural discovery to the community.
"My Workflow for Understanding LLM Architectures A learning-oriented workflow for understanding new open-weight model releases Many people asked me over the past months to share my workflow for how I come up." — MAGAZINE.SEBASTIANRASCHKA
Commentary: This workflow formalizes a new layer of the evaluation stack: architectural forensics. It signals that for open models, the definitive technical specification is now the implemented code, not the accompanying paper, which may be a marketing document. This elevates platforms like Hugging Face from mere distribution hubs to essential reference libraries, and it creates a tangible skill gap between those who can parse configs and transformers code and those who rely on secondary summaries. The explicit inapplicability to closed models like GPT-4 underscores a hardening bifurcation in how technical intelligence is gathered across the AI landscape.
Date: Sat, 18 Apr 2026 11:24:36 GMT
URL: https://magazine.sebastianraschka.com/p/workflow-for-understanding-llms
AI Sentiment Score: Negative (75%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Promptimus: Improving already good LLM prompts with zero manual engineering – Northwest Quantum (Nwquantum.Uw.Edu)
Summary: Northwest Quantum researchers have published a paper detailing Promptimus, a method for automatically optimizing already well-engineered LLM prompts. The system uses a metric-analyzer agent to diagnose failure points and a feedback loop to generate targeted improvements, operating in either a full-rewrite ‘standard mode’ or a surgical ‘edit mode’ for preserving complex business logic. It is model-agnostic and sample-efficient, requiring only 20-50 development examples. The paper reports it outperformed six leading baselines on 16 of 20 public benchmarks, with significant gains in enterprise tasks like complex API generation and multimodal classification.

Why it matters: This signals a shift from generative prompt engineering to automated, diagnostic refinement, directly addressing the costly enterprise challenges of model migration and performance plateauing for production-grade systems.
Context: Automated prompt optimization has historically struggled to improve upon carefully crafted, domain-specific prompts, often resorting to generic rewrites that risk breaking embedded logic. The rapid evolution of foundation models compounds this, creating recurring migration costs.
"Promptimus achieves the best result on 16 of 20 benchmarks and ties on one, outperforming all six baselines on average (0.792 vs. 0.765 for the best-of-six baseline). The largest gains appear on tasks where the metric has a decomposable structure." — NWQUANTUM.UW.EDU
Commentary: The move from generative to diagnostic optimization reframes prompt engineering as a continuous debugging process, lowering the barrier to adopting new models and squeezing marginal gains from mature systems. Its ‘edit mode’ is particularly consequential for enterprises, as it treats prompts as version-controlled assets with structured logic, mitigating the regression risk of full rewrites. If integrated into platforms like Amazon Bedrock as indicated, it could institutionalize a new layer of automated prompt management, shifting competitive advantage towards systematic, metric-driven iteration cycles.
Date: May 14, 2026 12:00 AM ET
URL: https://nwquantum.uw.edu/2026/05/14/promptimus-improving-already-good-llm-prompts-with-zero-manual-engineering/
AI Sentiment Score: Negative (66%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.Evaluating Prompting and Execution-Based Methods for Deterministic Computation in LLMs (Arxiv)
Summary: A 2026 arXiv preprint systematically evaluates the ability of large language models to perform deterministic, error-free computation on tasks like binary counting and longest substring detection. It finds that standard prompting methods, including Chain-of-Thought and Least-to-Most, achieve only moderate accuracy, while Program-of-Thought—which generates executable code for an external interpreter—achieves perfect results. The authors also demonstrate that a small, domain-specific model (CodeT5-small) can be trained to generate the required programs with perfect accuracy and minimal cost. The core finding is that LLMs appear to simulate reasoning rather than reliably execute exact symbolic computation, pointing to a fundamental architectural limitation.
Why it matters: This work provides empirical rigor to a critical debate about LLM capabilities, clarifying the boundary between probabilistic pattern-matching and reliable symbolic execution, which has direct implications for system design and trust in automated reasoning.
Context: The debate over whether LLMs possess true reasoning abilities or are sophisticated statistical parrots has been largely philosophical; this study introduces a controlled, synthetic benchmark to test deterministic performance, moving the discussion from speculation to falsifiable claims.
"Our results show that standard prompting methods achieve only moderate accuracy on sequence-based tasks. CoT provides limited improvement, while Least-to-Most suffers from error accumulation. In contrast, PoT achieves perfect accuracy by generating executable code and delegating computation to an external interpreter." — ARXIV
Commentary: This validates the emerging architectural pattern of using LLMs as high-level planners or spec generators, offloading precise execution to dedicated, verifiable tools—a shift that redefines the LLM’s role in production systems. The successful fine-tuning of a small model for perfect performance suggests a path toward cost-effective, specialized components, potentially fragmenting the ‘generalist’ model market. For developers, it mandates a more modular, tool-calling approach for any application requiring deterministic outputs, increasing system complexity but also auditability.
Date: May 04, 2026 12:00 AM ET
URL: https://arxiv.org/abs/2605.03227
AI Sentiment Score: Positive (42%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Position: Let’s Develop Data Probes to Fundamentally Understand How Data Affects LLM Performance (Arxiv)
Summary: A position paper accepted to ICML 2026 argues that the field lacks a fundamental understanding of how data characteristics affect LLM performance across training, tuning, and inference. The authors propose moving beyond compute-intensive empirical heuristics by developing ‘data probes’—synthetic sequences generated from defined random processes. Observing model behavior on these controlled probes could systematically reveal how statistical properties influence generalization and robustness, grounding the study of data in theoretical concepts like typical sets.
Why it matters: This signals a shift in research focus from scaling compute and dataset size to understanding the intrinsic properties of data, which could lead to more efficient, predictable, and interpretable model development.
Context: Current LLM development relies heavily on massive, opaque datasets and trial-and-error filtering, making data curation a major cost center and a source of unpredictable outcomes.
"Computer Science > Artificial Intelligence [Submitted on 11 May 2026] Title:Position: Let’s Develop Data Probes to Fundamentally Understand How Data Affects LLM Performance View PDF HTML (experimental)Abstract:Data is fundamental to large language." — ARXIV
Commentary: If operationalized, this approach could transform data curation from an artisanal craft into an analytical engineering discipline. It directly challenges the prevailing ‘more data is better’ scaling paradigm by seeking causal levers within data structure. Success would lower compute barriers for effective training and create a new class of diagnostic tools for model robustness, potentially shifting competitive advantage to teams with superior data science over raw data aggregation. The reference to theoretical concepts like typical sets is a deliberate bid to elevate the discourse from empirical results to falsifiable theory.
Date: Thu, 21 May 2026 00:00:00 -0400
URL: https://arxiv.org/abs/2605.18801
AI Sentiment Score: Negative (57%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Operationalizing Document AI: A Microservice Architecture for OCR and LLM Pipelines in Production (Arxiv)
Summary: A research team from arXiv details a production-ready microservice architecture for document AI, bridging the gap between academic models and industrial-scale operation. The system orchestrates classification, OCR, and LLM-based field extraction to process thousands of multi-page documents per hour. Key design choices include a hybrid classification approach, decoupling GPU inference from CPU orchestration, and asynchronous handling of I/O-bound tasks. Profiling revealed that OCR latency, not LLM parsing, is the dominant bottleneck, and system saturation is dictated by shared GPU capacity, not the number of workers.
Why it matters: It provides a concrete, empirically validated blueprint for scaling document intelligence beyond benchmarks, directly addressing the operational friction that stalls enterprise AI deployments.
Context: The AI industry is grappling with a ‘last-mile’ problem where advanced models fail in production due to unaddressed systems engineering, latency, and cost constraints.
"Using batch profiling, we identified two surprising qualitative findings that shape production deployments: OCR, not language-model parsing, dominates end-to-end latency, and the system saturates at a concurrency determined by shared GPU-inference capacity rather than worker count." — ARXIV
Commentary: The findings invert the common assumption that LLM inference is the primary scaling challenge, forcing a reallocation of optimization effort and hardware budgets toward OCR infrastructure. This architectural pattern signals a maturation phase where the value of document AI shifts from model accuracy to total system throughput and cost-per-document, favoring engineering teams that can manage heterogeneous, latency-sensitive pipelines.
Date: Thu, 21 May 2026 00:00:00 -0400
URL: https://arxiv.org/abs/2605.18818
AI Sentiment Score: Negative (85%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Evaluating the Utility of Personal Health Records in Personalized Health AI (Arxiv)
Summary: A study from Google Research and academic collaborators evaluates the utility of personal health records (PHRs) as context for large language models (LLMs) answering patient health queries. Using Gemini 3.0 Flash and a dataset of 2,257 queries matched with de-identified PHRs, the research found statistically significant improvements in answer helpfulness when PHR data was provided, compared to no context. The study also developed a new evaluation framework that identified specific LLM failure modes, such as temporal disorientation and rare confabulations, when parsing complex clinical notes.
Why it matters: This research provides a concrete, evaluative framework for a critical pre-market bottleneck in personalized health AI: reliably grounding LLM outputs in complex, unstructured patient data, while quantifying the specific risks introduced.
Context: The push for patient-centric AI health tools is accelerating, but their practical utility hinges on models accurately interpreting messy, longitudinal clinical data without introducing dangerous hallucinations.
"We see significant improvements in the helpfulness of answers to all question types with PHR data (p < 0.001, paired t-test). We also observe potential gains in safety, accuracy, relevance and personalization of answers. Our PHR evaluation framework further identifies gaps in LLM understanding of particular aspects of complex PHRs, such as temporal disorientation, and rare but meaningful confabulations." — ARXIV
Commentary: The work shifts the conversation from hypothetical potential to measurable, if partial, utility, providing a necessary benchmark for product development. The identification of ‘temporal disorientation’ as a specific error mode is a crucial insight for any system handling longitudinal health data. This establishes a baseline for what ‘good enough’ looks like for PHR-augmented LLMs before clinical deployment, setting a higher bar for startups and incumbents alike. The methodology itself—pairing automated and clinician evaluation—may become a de facto standard for validating health AI assistants.
Date: Thu, 21 May 2026 00:00:00 -0400
URL: https://arxiv.org/abs/2605.18937
AI Sentiment Score: Positive (40%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.PPO guided Agentic Pipeline for Adaptive Prompt Selection and Test Case Generation (Arxiv)
Summary: A research team proposes an agentic pipeline for software testing that uses Proximal Policy Optimization (PPO) to adaptively select prompts for a Large Language Model. The system first optimizes source code, then uses an 11-dimensional state vector of code metrics to guide an LLM through eight different test-generation strategies. Experiments on benchmark programs show it outperforms existing tools like CBMC and kS-LLM++ in branch and line coverage, particularly at higher loop bounds.
Why it matters: This demonstrates a concrete path toward automating high-quality test generation for complex systems, moving beyond static prompting to a dynamic, feedback-driven process that could lower verification costs and improve software reliability.
Context: Current LLM-based test generation often relies on fixed prompting strategies, which can miss edge cases in complex, nested code. Reinforcement learning has been explored for code generation, but its application to orchestrating prompt selection for systematic testing is a newer, more operational frontier.
"From experiments conducted on twenty benchmark programs, it is evident that the proposed approach, PPO-LLM, outperforms CBMC, kS-LLM, and kS-LLM++ in terms of branch and line coverage in almost all cases, for various loop bound values ranging from BOUND~1 to BOUND~2000." — ARXIV
Commentary: The shift from a static to an adaptive, RL-guided prompt selector represents a material change in developer workflow for quality assurance. It suggests a future where testing pipelines are self-optimizing agents, reducing the manual prompt engineering burden and potentially uncovering vulnerabilities static methods miss. The use of concrete code complexity and coverage metrics as the state vector grounds the approach in traditional software engineering practice, aiding adoption. However, the computational cost of training the PPO policy for each new codebase remains a barrier to real-time use.
Date: May 01, 2026 12:00 AM ET
URL: https://arxiv.org/abs/2605.00942v1
AI Sentiment Score: Negative (70%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Post ID: c1676542