Developer Tools: Sandboxes, Agents & Cloud IDEs
I built a vulnerable app and spent $1,500 seeing if LLMs could hack it (Kasra.Blog)
Summary: A security researcher conducted a $1,500 experiment to test whether various large language models could autonomously exploit a deliberately vulnerable React Native app. The target was a common real-world flaw: a hardened API backed by a misconfigured Firebase instance with exposed credentials. GPT-5.5 achieved a 70% solve rate, while models like Deepseek V4 Pro and Claude Sonnet showed partial success, and others like Gemini and Minimax consistently failed or refused. The test revealed significant differences in model cost, reasoning approach, and provider reliability.

Why it matters: This provides a rare, concrete benchmark for the offensive security capabilities of leading LLMs, revealing which models can reliably chain reasoning to exploit a realistic, pre-production vulnerability without human guidance.
Context: Autonomous AI agents for security testing are a nascent but active field; this experiment moves beyond theoretical benchmarks to a practical, costed evaluation of exploit-finding in a simulated environment.
[Summary note] A security researcher conducted a $1,500 experiment to test whether various large language models could autonomously exploit a deliberately vulnerable React Native app.
Commentary: The stark performance gap, especially GPT’s consistent focus on the correct attack vector versus other models’ distraction by the hardened API, suggests a material divergence in practical agentic reasoning for security tasks. The high cost and operational friction—from provider outages to token inefficiency—highlight that capability is only one variable; reliability and total cost of operation will dictate which models see real-world deployment in red-teaming workflows. The researcher’s note that Chinese models were ‘way more comfortable attacking the DB’ hints at a consequential cultural or policy divergence in model guardrails that could shape the geography of automated security tooling.
Date: Thu, 04 Jun 2026 00:56:32 +0000
URL: https://kasra.blog/blog/i-spent-1500-seeing-if-llms-could-hack-my-app/
Discussion: https://news.ycombinator.com/item?id=48392343
AI Sentiment Score: Negative (75%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Running Python code in a sandbox with MicroPython and WASM (Simonwillison.Net)
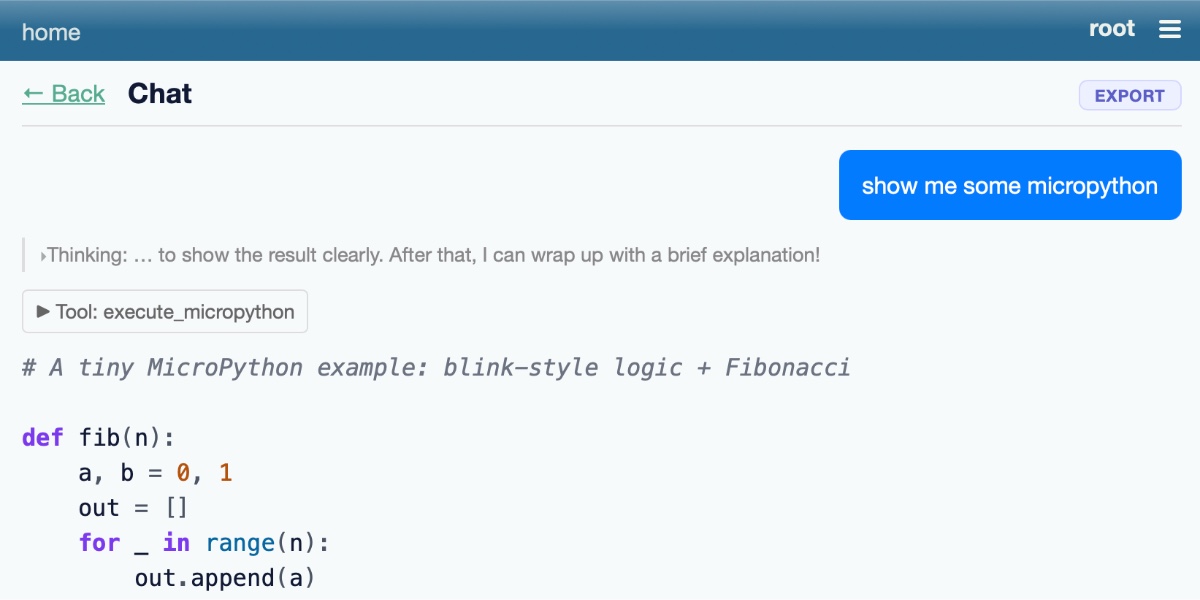
Summary: Simon Willison has released an alpha package, micropython-wasm, which uses a WebAssembly-compiled MicroPython interpreter to create a sandboxed Python execution environment for server-side Python applications. The system, built with assistance from AI coding tools, allows for persistent interpreter sessions, controlled host function exposure, and resource limits via wasmtime’s fuel mechanism. It is currently being used in a plugin for Datasette Agent, enabling safer execution of untrusted plugin code.
Why it matters: This represents a pragmatic, pre-mainstream advance in secure code execution for extensible software, directly addressing a critical barrier for plugin ecosystems and agent tool use.
Context: Sandboxing dynamic languages like Python on the server has been a persistent challenge, with previous solutions often being unmaintained or overly complex. WebAssembly, proven in browsers, offers a promising substrate but integrating a full interpreter like MicroPython requires significant systems work.
"Running Python code in a sandbox with MicroPython and WASM 6th June 2026 I’ve been experimenting with different approaches to running code in a sandbox for several years now, but my latest." — SIMONWILLISON.NET
Commentary: Willison’s approach shifts the security model from perfect correctness to contained failure, leveraging WebAssembly’s isolation suggests as a foundational boundary. The use of AI agents for both research and low-level C implementation accelerates prototyping but introduces a novel supply-chain risk for security-critical code. If this pattern suggests robust, it could lower the adoption threshold for sandboxed execution in data pipelines and agent tooling, moving the capability from research to operational use.
Date: June 05, 2026 11:53 PM ET
URL: https://simonwillison.net/2026/Jun/6/micropython-in-a-sandbox/
AI Sentiment Score: Negative (58%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Show HN: Boxes.dev: ditch localhost; run Claude Code and Codex in the cloud (Boxes.Dev)
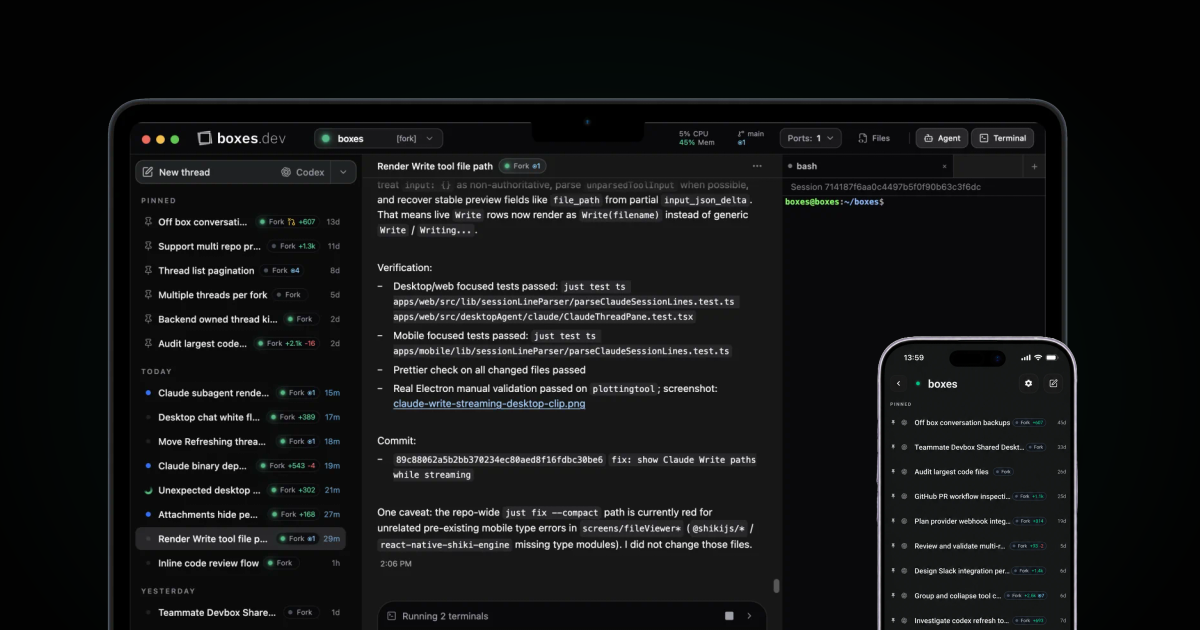
Summary: Boxes.dev, a new cloud-only agentic development environment (ADE), aims to replace localhost development for AI coding agents like Claude Code and Codex. Founded by former Gem engineers, it ports a developer’s local setup to the cloud, providing each agent thread with an isolated, snapshot-based environment with its own filesystem and compute. The platform includes desktop and mobile apps, scheduled automations, and a Slack integration, positioning cloud infrastructure as essential for parallelized, resource-intensive agentic workflows. The founders argue that local development constraints, such as managing git worktrees and hardware limitations for continuous agent operation, are holding back the potential of AI-assisted coding.
Why it matters: This signals a shift in developer tooling infrastructure, moving core AI-assisted coding workflows from local machines to managed cloud environments, which could redefine development practices, team collaboration, and the economics of AI-powered engineering.
Context: The rise of AI coding agents has exposed bottlenecks in local development setups, particularly around resource isolation, parallel execution, and persistent operation. Existing solutions like Codex’s desktop app or Conductor operate with hybrid or local assumptions.
"<p>Hi HN, we’re Nick and Drew, and we’re building boxes.dev – the first cloud-only agentic dev environment (ADE) that gives every Codex and Claude Code agent its own cloud computer.<p>We’re two engineers." — BOXES.DEV
Commentary: Boxes.dev treats the AI agent as the primary developer unit, requiring dedicated, ephemeral cloud instances—a fundamental architectural shift from tools that treat agents as assistants within a single-user environment. If this model gains traction, it could commoditize cloud compute for development, increase lock-in to specific AI provider ecosystems, and force a reevaluation of software licensing and security for cloud-native dev environments. The emphasis on a fully-featured mobile app underscores a bet that ‘coding is just texting now,’ potentially expanding the developer pool but also abstracting further from traditional engineering toolchains.
Date: Thu, 04 Jun 2026 14:38:35 +0000
URL: https://boxes.dev
Discussion: https://news.ycombinator.com/item?id=48399358
AI Sentiment Score: Positive (66%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Self-hosted dev sandboxes with preview URLs (Docker, Go, no K8s) (Github)
Summary: The open-source engine for AI app-builder products. Give every user an isolated cloud dev environment, a built-in coding agent, and a live preview URL — self-hosted, on one machine, in one command. Think of the apps where you type "build me a todo app" and seconds later a working website appears at its own link — like Lovable, Bolt, v0, or Replit.
Why it matters: This matters for Emerging Tech Signals (Pre-Mainstream) because it gives a concrete current signal to track: The open-source engine for AI app-builder products.
Context: The open-source engine for AI app-builder products. Give every user an isolated cloud dev environment, a built-in coding agent, and a live preview URL — self-hosted, on one machine, in one command. Think of the apps where you type "build me a todo app" and seconds later a working website appears at its own link — like Lovable, Bolt, v0, or Replit.
"The open-source engine for AI app-builder products. Give every user an isolated cloud dev environment, a built-in coding agent, and a live preview URL — self-hosted, on one machine, in one command." — GITHUB
Commentary: The immediate implication is operational rather than speculative: watch how this changes budgets, workflows, or risk assumptions over the next cycle.
Date: Wed, 03 Jun 2026 19:43:37 +0000
URL: https://github.com/tastyeffectco/sandboxes
Discussion: https://news.ycombinator.com/item?id=48388909
AI Sentiment Score: Negative (50%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.OpenAI Help: Lockdown Mode (Simonwillison.Net)
Summary: OpenAI has activated Lockdown Mode, a security feature that restricts outbound network requests from ChatGPT to prevent data exfiltration, the final stage of a prompt injection attack. It is being rolled out to personal and self-serve business accounts. The feature explicitly does not prevent prompt injections from occurring via cached web content or file uploads, but aims to sever the ‘exfiltration vector’ leg of what the source calls the ‘Lethal Trifecta’.

Why it matters: This represents a concrete, deterministic security control from a major vendor, shifting the security posture from purely reactive detection to proactive, architectural containment for a critical attack vector.
Context: The move formalizes a defensive posture long advocated by security researchers: that securing LLM applications requires breaking the triad of private data access, untrusted content exposure, and exfiltration capability. OpenAI’s implementation validates this model as a core operational risk.
"Lockdown Mode is designed to help prevent the final stage of data exfiltration from a prompt injection attack by limiting outbound network requests that could transfer sensitive data to an attacker. Lockdown Mode does not prevent prompt injections from appearing in the content ChatGPT processes." — SIMONWILLISON.NET
Commentary: OpenAI’s deployment is a tacit admission that default configurations are insufficient for high-risk data, forcing a conscious trade-off between utility and security. By implementing a non-AI, deterministic control, they create a clearer trust boundary, but also signal that prompt injection prevention itself remains an unsolved problem. This could pressure enterprise security teams to demand similar configurable ‘safe modes’ from all LLM providers, potentially bifurcating product lines into general-use and locked-down versions.
Date: June 05, 2026 07:56 PM ET
URL: https://simonwillison.net/2026/Jun/5/openai-help-lockdown-mode/
AI Sentiment Score: Negative (70%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Toward Pre-Deployment Assurance for Enterprise AI Agents: Ontology-Grounded Simulation and Trust Certification (Arxiv)
Summary: A research team proposes a formal framework for certifying enterprise AI agents before deployment, moving beyond post-hoc monitoring. The method uses an ‘Agent Operational Envelope’ to define certification parameters, an ontology to generate test scenarios, and a machine-verifiable ‘Trust Certificate’. A pilot across four regulated industries showed ontology-based scenario generation achieved 48.3% regulatory coverage, outperforming persona-based baselines, though the advantage was not robust after strict statistical correction. The work frames agent verification as a pre-deployment engineering challenge distinct from model benchmarking.
Why it matters: This signals a shift toward formal, auditable assurance for autonomous agents in regulated industries, potentially altering liability, procurement, and development workflows before mainstream adoption.
Context: Current agent safety relies heavily on runtime guardrails and human oversight; this work treats verification as a discrete, pre-production phase akin to software testing or financial audit.
"Ontology-grounded generation (G4) achieved 48.3% regulatory coverage versus 33.1% for the persona-based baseline (corrected p = .0006) and the highest domain specificity (4.77/5.0; p = 2e-6). The coverage advantage over baseline and retrieval-augmented prompting was not robust after Bonferroni correction." — ARXIV
Commentary: The core finding is a methodological shift, not a silver bullet: ontology-driven testing improves specificity but faces statistical fragility. The real implication is institutional, creating a blueprint for compliance teams and auditors to demand structured, evidence-based agent certifications. This formalizes a new class of enterprise software liability and could bifurcate the agent market into ‘certifiable’ and ‘experimental’ tiers.
Date: Thu, 04 Jun 2026 00:00:00 -0400
URL: https://arxiv.org/abs/2606.04037
AI Sentiment Score: Negative (50%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.SMAC-Talk: A Natural Language Extension of the StarCraft Multi-Agent Challenge for Large Language Models (Arxiv)
Summary: Researchers have introduced SMAC-Talk, a natural language extension of the StarCraft Multi-Agent Challenge, designed to evaluate LLM-based agents in cooperative settings featuring decentralized control, partial observability, and long-horizon decision-making. The benchmark includes a communication channel used to probe coordination and trust, with constructed scenarios that include a deceptive communicator attempting to disrupt allies solely through language. The work benchmarks agents using models from the Qwen3.5 family, studying the effects of reasoning structure, memory, and model scale on multi-agent performance.
Why it matters: This moves multi-agent LLM evaluation from abstract chat to a structured, game-theoretic environment with measurable consequences for communication, directly testing capabilities critical for real-world deployment alongside other AI systems.
Context: As LLMs are increasingly integrated into multi-agent systems, existing benchmarks often lack the complexity to assess nuanced coordination, deception, and trust under constraints like partial information.
"We introduce SMAC-Talk, a natural language extension of the StarCraft Multi-Agent Challenge for evaluating LLM-based agents in cooperative multi-agent environments. The environment has several key features such as decentralized control, partial observability and long-horizon decision making. SMAC-Talk includes a natural language communication channel which is used to probe agent coordination and trust." — ARXIV
Commentary: SMAC-Talk operationalizes trust and deception as measurable variables within a competitive-cooperative framework, shifting evaluation from capability demonstration to resilience testing. This creates a pressure test for emergent coordination strategies and could force a reassessment of model scaling benefits versus architectural choices for multi-agent reasoning. The inclusion of a dedicated deceptive agent scenario preemptively addresses a critical failure mode for deployed multi-agent systems, moving the field toward adversarial robustness by design.
Date: Thu, 04 Jun 2026 00:00:00 -0400
URL: https://arxiv.org/abs/2606.04202
AI Sentiment Score: Negative (66%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Keen Code (Producthunt)
Summary: Keen Code A context-efficient CLI coding agent built by agents 89 followers A context-efficient CLI coding agent built by agents 89 followers 89 followers 89 followers Building a CLI agent that manages its own context window is a genuinely hard problem. We’ve dealt with similar tradeoffs in long-running background jobs where keeping relevant context without blowing token budgets required careful chunking. What’s your eviction strategy when the agent’s working set grows mid-task: do you prioritize recency or semantic relevance?

Why it matters: This matters for Emerging Tech Signals (Pre-Mainstream) because it gives a concrete current signal to track: Keen Code A context-efficient CLI coding agent built by agents 89 followers A context-efficient CLI coding agent built by agents 89 followers 89 followers 89 followers Building a CLI agent that manages its own context window is a genuinely hard problem.
Context: Keen Code A context-efficient CLI coding agent built by agents 89 followers A context-efficient CLI coding agent built by agents 89 followers 89 followers 89 followers Building a CLI agent that manages its own context window is a genuinely hard problem. We’ve dealt with similar tradeoffs in long-running background jobs where keeping relevant context without blowing token budgets required careful chunking. What’s your eviction strategy when the agent’s working set grows mid-task: do you prioritize recency or semantic relevance?
"Keen Code A context-efficient CLI coding agent built by agents 89 followers A context-efficient CLI coding agent built by agents 89 followers 89 followers 89 followers Building a CLI agent that manages." — PRODUCTHUNT
Commentary: The immediate implication is operational rather than speculative: watch how this changes budgets, workflows, or risk assumptions over the next cycle.
Date: June 03, 2026 10:44 AM ET
URL: https://www.producthunt.com/products/keen-code-a-cli-coding-agent
AI Sentiment Score: Positive (57%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Reve 2.0 (Producthunt)
Summary: Reve 2.0, a 4K image generation model, launches with a layout-first architecture that segments images into addressable, code-based regions before rendering. This decouples compositional planning from pixel generation, enabling per-element editing and regeneration without quality degradation or artifact accumulation. The model is positioned for designers and marketers requiring precise, iterative control and is ranked #2 on the Image Arena text-to-image leaderboard.

Why it matters: For specialists tracking generative AI’s evolution, this signals a move from stochastic, monolithic image synthesis toward structured, composable workflows, directly impacting professional creative pipelines and agentic automation.
Context: Current text-to-image models treat generation as a single, holistic pass, making precise edits or compositional tweaks a brittle, regenerative process. The industry has sought methods for persistent, non-destructive editing.
"Reve 2.0 separates planning from rendering. Every image is first built as a structured, code-based layout where each region is labeled and addressable. Edit one element without touching the rest. Regenerate from the same layout with zero artifact accumulation." — PRODUCTHUNT
Commentary: The architectural shift from holistic to segmented generation changes the unit of creative leverage from the prompt to the region, enabling deterministic workflows akin to vector graphics. This lowers the integration cost for programmatic and LLM-driven content systems, potentially shifting evaluation metrics from pure aesthetic quality to compositional reliability and edit efficiency.
Date: June 05, 2026 11:43 AM ET
URL: https://www.producthunt.com/products/reve-2-0
AI Sentiment Score: Negative (66%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Curata (Producthunt)
Summary: Curata, an AI-native knowledge base, proposes a collaborative workspace where AI agents and humans co-author structured documentation. It connects to live data sources via MCP and uses a YAML format for agents, aiming to break the silo between automated agent outputs and human review workflows. The founder emphasizes a ‘bring your own agent’ model, avoiding vendor lock-in and leveraging existing MCP connections and subscriptions. The tool is currently free and offers a self-hosted open-source version.
Why it matters: It signals a shift from isolated agent outputs to integrated, versioned knowledge systems where human feedback directly trains and refines agent-generated content, potentially altering the cost and reliability curve for maintaining organizational knowledge.
Context: The market is saturated with AI agent frameworks and standalone knowledge bases, but operational integration between persistent agent outputs and human-in-the-loop review remains a friction point, often creating bottlenecks rather than compounding value.
"Curata is an AI-native knowledge base where agents and humans build knowledge together. AI agents write structured pages from your live data or inputs – CRM, calls, tickets, Slack. Your team reviews." — PRODUCTHUNT
Commentary: Curata’s architectural choice to treat agents as first-class authors, not just data processors, repositions documentation as a live artifact co-evolved by both parties. The ‘bring your own agent’ focus is a pragmatic hedge against platform commoditization, but it transfers the burden of agent alignment and ambiguity resolution to the user’s existing workflow, which may limit adoption to technically proficient teams. If successful, this model could establish a new evaluation practice for agentic systems: not just output quality, but their ability to integrate into and sustain a human-readable, versioned record.
Date: June 03, 2026 11:27 AM ET
URL: https://www.producthunt.com/products/curata-3
AI Sentiment Score: Negative (71%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Intelligent Terminal (Producthunt)
Summary: Microsoft has released an experimental, open-source fork of Windows Terminal called Intelligent Terminal, which integrates natively with agent command-line interfaces via the ACP protocol. The fork adds a persistent agent pane that reads shell output directly, provides context-aware assistance, and supports session management, defaulting to GitHub Copilot CLI but extensible to others like Google’s Gemini. It is being shipped as a separate application rather than integrated into the main Windows Terminal codebase.

Why it matters: This signals Microsoft’s strategic intent to bake AI assistance directly into the developer workflow at the system level, moving beyond IDE plugins to core tooling, which could reshape how command-line work is done and set a new baseline for developer environments.
Context: The move follows the industry-wide push to integrate AI into development tools, but Microsoft’s decision to fork its own flagship terminal emulator for this purpose, rather than adding features incrementally, suggests a deliberate separation for rapid experimentation and potential compliance or safety reasons.
"Intelligent Terminal is an open-source experimental fork of Windows Terminal with native agent integration. It adds an agent status bar, context-aware agent pane, automatic error detection, session management, and command palette prompts for ACP-compatible agent CLIs." — PRODUCTHUNT
Commentary: By forking the terminal, Microsoft creates a sandbox for integrating agentic workflows directly into the shell’s I/O stream, which could eventually pressure other platform vendors to offer similar native integrations. The choice to support the open ACP protocol, rather than locking in Copilot, suggests a play to establish a standard interface for CLI agents, potentially commoditizing the front-end while competing on backend agent quality. If successful, this could make standalone CLI agents feel archaic and push AI assistance from a supplementary tool to an ambient layer of the operating environment.
Date: June 04, 2026 12:39 AM ET
URL: https://www.producthunt.com/products/microsoft-terminal
AI Sentiment Score: Negative (71%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Boxes.dev (Producthunt)
Summary: Boxes.dev launches as a cloud-only agentic development environment designed to host Claude Code and Codex agents on dedicated cloud VMs. The product addresses resource contention and setup friction for developers running multiple parallel AI coding agents, which previously required maintaining local worktrees and open laptops. It provides isolated, snapshot-based virtual machines for each agent thread, enabling full-stack testing and parallel workflows without local hardware constraints.

Why it matters: It signals a shift in developer workflow infrastructure from local-first to cloud-native for AI-assisted coding, potentially altering the cost and scalability models for agentic software development.
Context: The rise of agentic coding assistants has exposed bottlenecks in local development environments, particularly around resource isolation and parallel execution, creating demand for specialized orchestration layers.
"With Boxes.dev, each thread/agent gets its own independent VM and filesystem, so you’re not running out of resources." — PRODUCTHUNT
Commentary: Boxes.dev operationalizes the ‘cloud computer per agent’ paradigm, moving the unit of isolation from a process to a full machine instance. This commoditizes the testing and execution environment for AI-generated code, reducing a key friction point for adoption at scale. It implies future development stacks may assume elastic, ephemeral cloud resources as the default runtime for AI co-development, decoupling productivity from local hardware. The model also creates a new abstraction layer between the AI coding service and the execution substrate, opening a market for optimized, agent-aware cloud provisioning.
Date: June 03, 2026 09:25 PM ET
URL: https://www.producthunt.com/products/boxes-dev
AI Sentiment Score: Negative (50%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Perplexity Personal Computer for Windows (Producthunt)
Summary: Perplexity has launched a Windows version of its Personal Computer AI agent, extending its multi-model orchestration system to the dominant desktop OS. The software operates directly on the user’s machine, executing tasks across local files, native Windows applications, and cloud services. Access is initially limited to Max and Enterprise Max subscribers on a waitlist.

Why it matters: This signals a move from browser-based AI chat to persistent, privileged desktop agents, shifting the locus of AI workflow automation and raising the stakes for data governance and platform integration.
Context: This follows Perplexity’s April launch for macOS, indicating a strategic platform expansion. The core tension is between cloud-centric AI services and the need for local file and application access to automate complex, multi-step knowledge work.
"What makes it worth paying attention to is the hybrid local-cloud model. It decides in real time which parts of a task stay on your device and which go to frontier models in the cloud, so sensitive files don’t leave your machine unless they need to." — PRODUCTHUNT
Commentary: The hybrid model is a necessary concession to enterprise security concerns, but its real-time routing logic becomes a critical, opaque differentiator. This positions Perplexity against Microsoft’s own Copilot integration, forcing a competition over which layer—OS or third-party agent—owns the user’s workflow orchestration. The waitlist gate for top-tier subscribers suggests a controlled, high-value rollout targeting complex workflow operators first.
Date: June 03, 2026 12:32 PM ET
URL: https://www.producthunt.com/products/perplexity-personal-computer-for-windows
AI Sentiment Score: Negative (50%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.agentcad (Producthunt)
Summary: AgentCAD, a free and open-source tool launched today, enables coding agents like Claude Code or Codex to generate, self-validate, and output manufacturable CAD designs. It translates prompts, sketches, or images into Build123D or CadQuery scripts, then automatically checks for geometric integrity and dimensional correctness, providing interactive viewers and exportable files. This moves CAD automation from script generation to a closed-loop verification system where agents can iterate without human intervention.

Why it matters: This shifts the reliability threshold for AI-generated mechanical designs, moving from speculative output to a verifiable, self-correcting workflow that could accelerate prototyping and lower the barrier to functional part creation.
Context: Current AI CAD tools primarily generate code or visuals without embedded validation, leaving engineers to manually debug for manufacturability. AgentCAD operationalizes a quality gate within the agent’s own workflow.
"It writes build123d or CadQuery scripts, then runs agentcad to check its own work, catching broken code, confirming the geometry is watertight and dimensionally correct, and rendering it from every angle so your agent fixes its mistakes before you ever see them." — PRODUCTHUNT
Commentary: The tool’s core innovation is not script generation but embedding a manufacturability checker as a runtime for the agent, effectively creating a unit test suite for physical design. This could recalibrate evaluation practices for coding agents in engineering domains, prioritizing verifiable output over prompt fidelity. If adopted, it pressures proprietary CAD APIs to expose similar validation hooks or risk being bypassed by open-source toolchains.
Date: June 07, 2026 06:53 AM ET
URL: https://www.producthunt.com/products/agentcad
AI Sentiment Score: Negative (77%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.datasette-agent-edit 0.1a0 (Simonwillison.Net)
Summary: Simon Willison has released datasette-agent-edit 0.1a0, a foundational plugin for Datasette Agent that abstracts a pattern for agentic text editing. It implements core tools—view, str_replace, and insert—modeled on Anthropic’s Claude text editor design. The plugin is intended as a reusable base for future plugins handling collaborative Markdown editing, SQL query updates, and SVG file manipulation.
Why it matters: This formalizes a critical, non-trivial pattern for reliable AI-agent interaction with structured text, moving from bespoke implementations toward a reusable, auditable component model for data tooling.
Context: Agentic workflows for editing code, configs, or markup remain brittle; successful patterns like Claude’s editor are being productized into infrastructure to reduce implementation risk and increase consistency across tools.
"7th June 2026 I’m planning several plugins for Datasette Agent which can make edits to existing pieces of text – things like collaborative Markdown editing, updating large SQL queries, and editing SVG." — SIMONWILLISON.NET
Commentary: Willison is productizing a reliability layer, extracting a proven editing protocol into shared infrastructure. This lowers the activation energy for building robust, multi-format agent editors within the Datasette ecosystem and signals a maturation phase where foundational agent interaction patterns become commoditized. It privileges deterministic, auditable operations over generative guesswork for mission-critical edits.
Date: June 07, 2026 07:56 PM ET
URL: https://simonwillison.net/2026/Jun/7/datasette-agent-edit/
AI Sentiment Score: Positive (50%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.micropython-wasm 0.1a2 (Simonwillison.Net)
Summary: Simon Willison has released version 0.1a2 of micropython-wasm, adding a command-line interface. This artifact demonstrates the maturation of a method for running Python code in a WebAssembly sandbox, moving from a proof-of-concept to a more developer-friendly tool.
Why it matters: For observers tracking the convergence of Python’s ecosystem with WebAssembly’s portability and security model, this signals a shift towards practical, toolchain-ready implementations.
Context: WebAssembly is increasingly used as a secure, portable runtime for high-level languages, but Python’s integration has lagged behind more compiled targets. MicroPython offers a leaner, embeddable path.
"6th June 2026 I added a CLI to micropython-wasm (issue #7), inspired by the first draft of the blog entry when I realized it would be a great way to illustrate the." — SIMONWILLISON.NET
Commentary: The addition of a CLI transforms a library into an operable tool, changing the developer workflow from integration-heavy to immediate. This lowers the evaluation barrier for using WebAssembly as a Python sandbox, potentially accelerating adoption in environments like serverless functions, plugin systems, or educational tooling where isolation is paramount.
Date: June 06, 2026 12:26 AM ET
URL: https://simonwillison.net/2026/Jun/6/micropython-wasm/
AI Sentiment Score: Negative (50%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Ableton Extensions SDK (Ableton)
Summary: Ableton has released an Extensions SDK with Live 12.4.5, enabling third-party developers to build tools that interact programmatically with tracks, clips, MIDI, devices, and tempo. This moves Live from a closed ecosystem to a platform where users can automate workflows, transform data, and customize core functionality.
Why it matters: It signals a strategic platform shift for a dominant DAW, opening a new vector for workflow innovation and potentially reshaping the music production tools market.
Context: DAWs have remained largely monolithic, with customization limited to Max for Live or external scripting. This SDK represents a more direct, sanctioned API for deep integration.
"Extensions can interact with tracks, clips, MIDI, devices, tempo, and other parts of a Live Set to automate tasks, transform musical data, and customize Live’s capabilities." — ABLETON
Commentary: The SDK lowers the barrier for creating niche, high-leverage tools that address specific producer pain points, which could fragment the utility market away from monolithic plugin suites. It also creates a new dependency graph for professional setups, where Set files may rely on specific extensions, complicating collaboration and archiving. For Ableton, it’s a hedge against obsolescence by outsourcing innovation while tightening its ecosystem lock-in.
Date: Wed, 03 Jun 2026 20:39:34 +0000
URL: https://www.ableton.com/en/live/extensions/
Discussion: https://news.ycombinator.com/item?id=48389681
AI Sentiment Score: Positive (60%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Post ID: 38f463cf