AI Agent Infrastructure and Automation
AI Builder Pulse — 2026-05-02 (Buttondown)
Summary: AI Builder Pulse — 2026-05-02 AI Builder Pulse — 2026-05-02 Today: 101 stories across 7 categories — top pick, "Grok 4.3", from Hacker News · 386 points. In this issue: – Tools & Launches (21) – Model Releases (10) – Techniques & Patterns (22) – Infrastructure & Deployment (10) – Notable Discussions (11) – Think Pieces & Analysis (21) – News in Brief (6) Today’s Top Pick Grok 4.3 (HN) Hacker News · 386 points xAI released Grok 4.3 with updated capabilities — high community engagement suggests notable benchmark or feature improvements worth evaluating against other frontier models. Tools & Launches Advanced Quantization Algorithm for LLMs (HN) Hacker News · 122 points Intel’s AutoRound is an advanced quantization library for LLMs that can significantly reduce model size and inference cost with minimal accuracy loss — strong community traction.
Why it matters: This matters for Emerging Tech Signals (Pre-Mainstream) because it gives a concrete current signal to track: AI Builder Pulse — 2026-05-02 AI Builder Pulse — 2026-05-02 Today: 101 stories across 7 categories — top pick, "Grok 4.3", from Hacker News · 386 points.
Context: AI Builder Pulse — 2026-05-02 AI Builder Pulse — 2026-05-02 Today: 101 stories across 7 categories — top pick, "Grok 4.3", from Hacker News · 386 points. In this issue: – Tools & Launches (21) – Model Releases (10) – Techniques & Patterns (22) – Infrastructure & Deployment (10) – Notable Discussions (11) – Think Pieces & Analysis (21) – News in Brief (6) Today’s Top Pick Grok 4.3 (HN) Hacker News · 386 points xAI released Grok 4.3 with updated capabilities — high community engagement suggests notable benchmark or feature improvements worth evaluating against other frontier models. Tools & Launches Advanced Quantization Algorithm for LLMs (HN) Hacker News · 122 points Intel’s AutoRound is an advanced quantization library for LLMs that can significantly reduce model size and inference cost with minimal accuracy loss — strong community traction.
"AI Builder Pulse — 2026-05-02 AI Builder Pulse — 2026-05-02 Today: 101 stories across 7 categories — top pick, "Grok 4.3", from Hacker News · 386 points. In this issue: – Tools." — BUTTONDOWN
Commentary: The immediate implication is operational rather than speculative: watch how this changes budgets, workflows, or risk assumptions over the next cycle.
Date: May 02, 2026 12:00 AM ET
URL: https://buttondown.com/ai-builder-pulse/archive/ai-builder-pulse-2026-05-02/
AI Sentiment Score: Negative (62%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Product Hunt Weekly 2026-04-23: AI Agent Infrastructure Boom … (Shareuhack)
Summary: Product Hunt’s weekly ranking signals a shift from pure software AI agent infrastructure to tangible hardware interfaces and integrated developer workflows. Anthropic’s rapid multi-product release, including Claude Code Desktop and Claude Desktop Buddy, demonstrates a push to embed its models into coding environments and physical devices. The top-ranked product, the Dune keypad, and the SpeakON MagSafe voice device indicate that AI’s next friction point is the human-machine interface, not just model capability. Meanwhile, open-source projects like Moonshot’s Kimi K2.6 are pushing multi-agent coordination benchmarks, and tools like Resend CLI 2.0 and InstantDB are streamlining backend infrastructure for agent deployment.

Why it matters: The convergence of AI with physical hardware and deeply integrated developer tools marks the transition from experimental agents to operational systems, reshaping productivity, development workflows, and competitive moats.
Context: The AI infrastructure layer has been dominated by cloud APIs and model performance; this week’s rankings show a clear pivot toward ergonomic integration, local execution, and hardware endpoints as the field matures.
"# Product Hunt Weekly 2026-04-23: AI Agent Infrastructure Boom, Platform Wars Heat Up, Hardware Revival … TL;DR: The biggest story this week is Anthropic shipping four products in rapid succession (Claude Opus." — SHAREUHACK
Commentary: The hardware surge (Dune, SpeakON, Claude Desktop Buddy) suggests the market is solving for latency, context-switching, and persistent agency—problems pure software struggles with. Anthropic’s bundled release strategy aims to lock developers into a full-stack Claude ecosystem before open-source multi-agent frameworks like Kimi gain operational traction. The rise of agent-native infrastructure (Resend CLI, InstantDB) indicates that evaluation is shifting from benchmark scores to deployment readiness and cost-per-task.
Date: April 23, 2026 12:00 AM ET
URL: https://www.shareuhack.com/en/posts/product-hunt-weekly-2026-04-23
AI Sentiment Score: Positive (50%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.From Policy to Proof: Closing the AI Evidence Gap — Govagentic (Govagentic.Ai)
Summary: The NAIC’s 12-state AI Systems Evaluation Tool pilot and the EU AI Act’s August 2026 compliance deadline are shifting AI governance from policy declarations to evidence-based verification. Regulators now demand structured technical documentation—model cards, performance logs, decision audit trails—demonstrating operational control. This creates a compliance gap for organizations lacking a ‘technical evidence stack’.

Why it matters: For insurers, tech vendors, and regulated entities, this signals the end of governance-by-assertion and the start of a costly, technically detailed audit regime.
Context: This follows a multi-year pattern of regulatory frameworks (GDPR, CCPA) maturing from principle to prescriptive technical standard, now applied to AI systems.
"Two developments in 2026 make that gap harder to ignore. The NAIC’s 12-state AI Systems Evaluation Tool pilot, live since March 2026, is asking insurers to produce technical documentation — not policy." — GOVAGENTIC.AI
Commentary: The NAIC pilot and EU AI Act harmonized standard prEN 18286 crystallize a pre-mainstream signal: AI governance is becoming a documentation and monitoring engineering problem. This will bifurcate the market between organizations that can produce auditable technical artifacts and those reliant on vendor marketing. It also creates a new service layer for compliance tooling and third-party assessment.
Date: April 20, 2026 12:00 AM ET
URL: https://govagentic.ai/insights/2026-04-20-the-evidence-gap
AI Sentiment Score: Negative (80%)
AI Credibility Score: 8.4/10 — High
Scores and text generated by AI analysis of the source article indicated.Catch up on AI — 2026-04-30 UTC | explainx.ai (Explainx.Ai)
Summary: The weekly AI digest for April 30, 2026, catalogs a landscape of specialized tooling and foundational shifts. Key signals include the operationalization of multi-agent systems like SuperMind and Symphony for business automation, the maturation of open-source voice models and developer environments, and competitive benchmarking between major AI labs on security and preparedness. The update also notes the continued push for local-first development and the formalization of agentic software development methodologies.

Why it matters: This snapshot reveals the transition from model-centric to workflow-centric AI, where the competitive edge lies in orchestration, developer tooling, and operational integration, not just raw model capability.
Context: The industry is moving beyond standalone LLM APIs toward integrated, multi-agent operating systems and specialized toolchains that promise to automate complex, end-to-end business and development processes.
"Bulletin · UTC Merged timeline: 14 items (blog publish time and listing createdAt in UTC). For registry-only weekly slices, use /new. Mistral Medium 3.5 is a flagship model designed for instruction-following, reasoning,." — EXPLAINX.AI
Commentary: The framing of AI as an ‘operating system’ signifies a strategic pivot from tool to infrastructure, locking in enterprise workflows. The emphasis on parallel execution and persistent memory suggests a move toward durable, stateful automation that could reshape organizational roles. Meanwhile, the parallel focus on local-first, open-source tooling (Gemma 4 on MLX, Invidious) indicates a countervailing pressure for sovereignty and control, setting up a core tension in the next-phase market.
Date: April 30, 2026 12:00 AM ET
URL: https://explainx.ai/catch-up-on-ai/2026-04-30
AI Sentiment Score: Negative (66%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.The AI Automation Pulse – Issue #13 – by Simeon Penev – Substack (Simeonpenev.Substack)
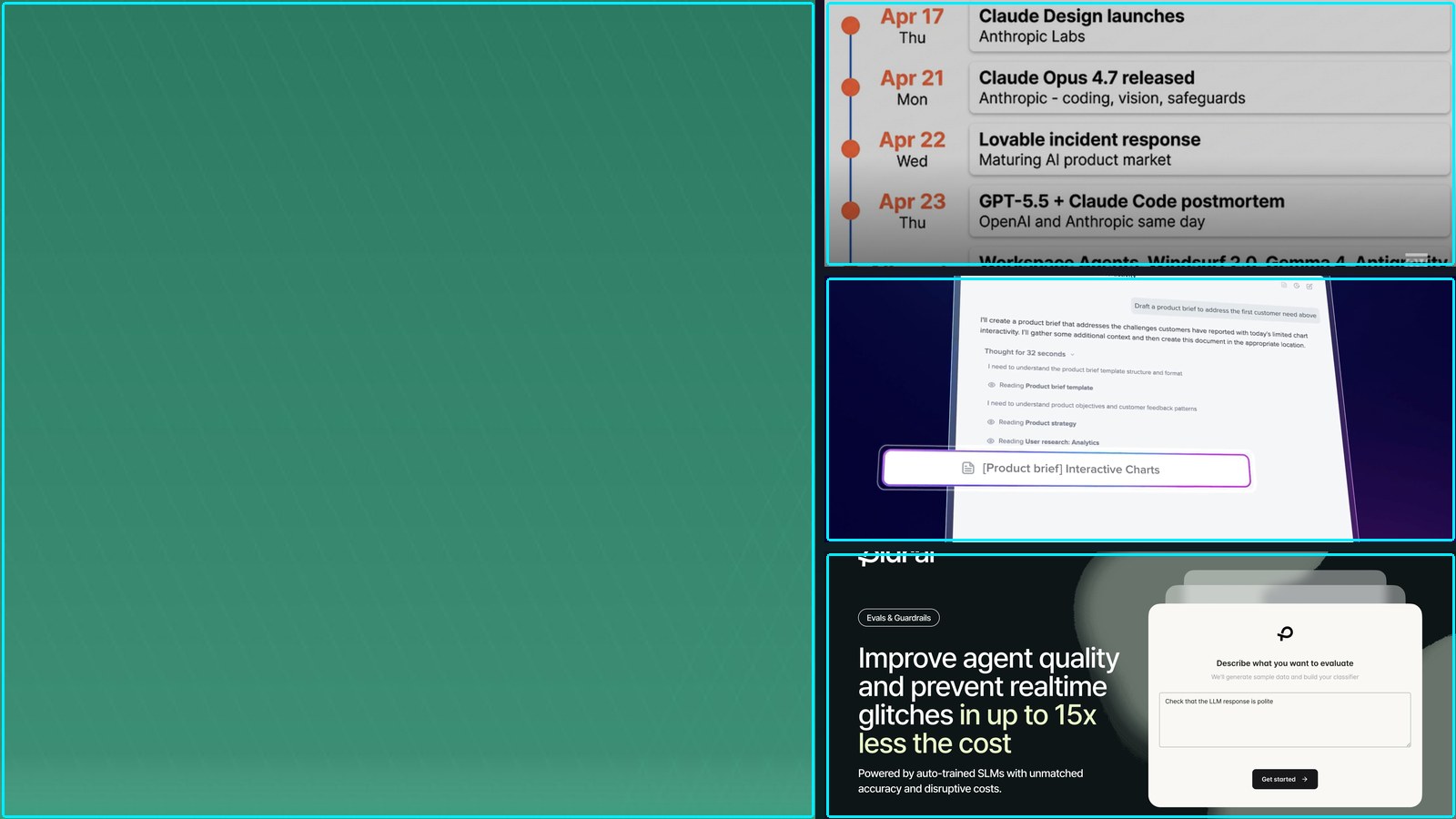
Summary: The AI automation landscape is consolidating around workflow integration and operational reliability. OpenAI’s workspace agents and Anthropic’s Claude Design signal a pivot from personal chat assistants to shared, persistent systems that orchestrate tasks across business tools. Concurrently, developer environments like Cursor and automation platforms like n8n are prioritizing agent delegation, visibility, and evaluation, indicating that the competitive edge now lies in workflow surfaces and execution trust, not just model capabilities.

Why it matters: For specialists tracking AI’s practical adoption, this shift marks the transition from experimental demos to infrastructure that reconfigures team collaboration and software development lifecycles.
Context: The narrative has evolved from benchmarking raw model performance to assessing how AI agents are embedded into production workflows, with major players now competing on platform integration and operational tooling.
"### What’s New in AI World (Apr 17-24, 2026) ## TL;DR – OpenAI’s workspace agents are the clearest sign this week that agents are moving from personal chat toys into shared team." — SIMEONPENEV.SUBSTACK
Commentary: This reframes agents as persistent organizational middleware, demanding new governance and security considerations. The focus on handoffs and cross-tool work suggests a coming wave of enterprise integration battles, where workflow lock-in may become as critical as model selection. Platforms that master delegation and state management will capture the operational value chain.
Date: April 24, 2026 12:00 AM ET
URL: https://simeonpenev.substack.com/p/the-ai-automation-pulse-issue-13
AI Sentiment Score: Neutral (50%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.Product Hunt Daily | 2026-04-30 (Producthunt.Programnotes.Cn)
Summary: Product Hunt’s April 30, 2026, listings reveal a concentrated push toward operationalizing AI through infrastructure, evaluation, and composability. Plurai abstracts agent guardrail creation into a ‘vibe coding’ workflow, KarmaBox commoditizes model inference into a portable compute pool, and Dreambase Skills packages business logic for agentic consumption. Concurrently, Open Wearables and Netlify Database signal a parallel maturation of foundational, open data layers.

Why it matters: These artifacts collectively shift the competitive landscape from model capability to developer ergonomics, system reliability, and data interoperability, defining the next phase of practical AI integration.
Context: The trend moves beyond foundational models toward the tooling and infrastructure required to deploy, evaluate, and compose AI reliably within existing systems and business logic.
"## 1. Plurai Tagline: Vibe-train evals and guardrails tailored to your use case Description: Vibe training for AI agent reliability. Describe what your agent should and should not do — Plurai generates." — PRODUCTHUNT.PROGRAMNOTES.CN
Commentary: Plurai’s approach, if viable, commoditizes a critical bottleneck—high-quality evaluation and safety fine-tuning—potentially lowering the barrier to reliable agent deployment but also abstracting away technical nuance that could mask failure modes. KarmaBox and Open Wearables represent a disaggregation of the AI stack, favoring portable, vendor-agnostic compute and data access over monolithic platforms. Together, they point to an ecosystem where AI capability is increasingly a function of integration plumbing and evaluation rigor, not just model weights.
Date: April 30, 2026 12:00 AM ET
URL: https://producthunt.programnotes.cn/en/p/product-hunt-daily-2026-04-30/
AI Sentiment Score: Negative (66%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.The Intake — Saturday, April 25, 2026 — Substratics (Substratics)
Summary: A researcher’s disclosure details a prompt-injection attack vector targeting agent code-review tools from Anthropic, Google, and GitHub, exploiting PR titles and issue bodies to exfiltrate credentials. The vulnerability is operationally significant because it leverages the agents’ own runtime environment against them. Concurrently, Anthropic’s Mythos preview reveals withheld zero-day discoveries, Google Deep Research ships with MCP integration, and the EU’s GPAI enforcement deadline looms, framing a week of structural admissions and pre-compliance positioning.

Why it matters: This exposes a foundational security flaw in agent tooling that is being deployed into high-trust CI/CD environments, forcing immediate operational changes and challenging the architectural assumptions of integrated AI systems.
Context: The disclosure arrives as agent-integration products rush to market ahead of impending EU AI Act enforcement, creating tension between rapid deployment and the ‘hardening’ expected for high-risk systems.
"Anthropic’s own system card on the affected GitHub Action describes the action as "not hardened against prompt injection," which means the vendor confirmed the diagnosis before the publication did." — SUBSTRATICS
Commentary: The vendor’s preemptive admission shifts the frame from a discovered bug to a known architectural limitation, forcing a reevaluation of agent trust boundaries. This, combined with the impending regulatory cliff, suggests a coming bifurcation between ‘hardened’ agent workflows for compliance-sensitive use cases and the current generation of vulnerable integrations.
Date: April 25, 2026 12:00 AM ET
URL: https://substratics.com/intake/2026-04-25/
AI Sentiment Score: Positive (50%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.Alpha Testing In The Real… (Spin.Atomicobject)
Summary: A developer details a product development workflow that prioritizes mechanical validation over technical implementation, using Figma for structural wireframing and Figma Make for interactive prototyping before writing any production code. This approach allowed for rapid iteration on core gameplay loops and user interaction patterns, generating behavioral data and identifying friction points prior to committing to a full stack. Only after this alpha phase did the project move to a TypeScript/React/Firebase implementation, where real logic and persistence were added. The final beta release then exposed further refinements needed in areas like streak tracking and mobile spacing.

Why it matters: It signals a maturation in pre-code design tooling, enabling a more rigorous, data-informed prototype phase that de-risks product development and redefines the engineering starting line.
Context: This reflects a broader shift in software development where high-fidelity, interactive prototyping tools are closing the gap between design mockups and functional demos, changing how product-market fit is validated.
"In the first phase of building my puzzle game, I wasn’t thinking about deployment or databases. I was thinking about mechanics, and whether the core loop was strong enough to justify building." — SPIN.ATOMICOBJECT
Commentary: The process elevates Figma Make from a presentation layer to a legitimate functional sandbox, shifting the ‘first commit’ milestone later in the lifecycle. This changes cost curves for indie developers and small teams, allowing more hypothesis testing before architectural lock-in. It also pressures engineering culture to accept prototype-level behavioral data as a valid input for technical design, potentially reducing wasted sprints on unvalidated features.
Date: April 22, 2026 12:00 AM ET
URL: https://spin.atomicobject.com/ai-working-prototype/
AI Sentiment Score: Negative (50%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.PPO guided Agentic Pipeline for Adaptive Prompt Selection and Test Case Generation (Arxiv)
Summary: A research team proposes a reinforcement learning-driven agentic pipeline that uses Proximal Policy Optimization (PPO) to adaptively select prompts for an LLM-based test case generator. The system first optimizes source code, then uses a policy network trained on code complexity and coverage metrics to choose from eight prompting techniques, aiming to maximize branch and line coverage. Experiments on benchmark programs show it outperforms static prompting strategies and established tools like CBMC and kS-LLM++, particularly in achieving near-perfect coverage on certain program suites.
Why it matters: This signals a shift from static, one-size-fits-all LLM prompting for code generation toward dynamic, context-aware agentic workflows, potentially raising the reliability and cost-effectiveness of automated software testing.
Context: Current LLM-assisted software engineering tools often rely on fixed prompting strategies, limiting their adaptability to complex, nested codebases. This work aligns with a broader trend of using lightweight reinforcement learning to steer LLM outputs for specific, measurable technical objectives.
"Computer Science > Software Engineering [Submitted on 1 May 2026] Title:PPO guided Agentic Pipeline for Adaptive Prompt Selection and Test Case Generation View PDF HTML (experimental)Abstract:Developing effective test cases capable of thoroughly." — ARXIV
Commentary: The method reframes prompt engineering from a manual, artisanal task into a learnable, automated policy, which could commoditize expertise in specialized domains like test generation. If this approach generalizes, it pressures tool vendors to integrate adaptive agentic layers, potentially altering developer workflows and the economics of software quality assurance. The focus on concrete metrics like branch coverage and code length reduction provides a clear, evaluable framework that moves beyond qualitative prompt ‘tips’.
Date: May 01, 2026 12:00 AM ET
URL: https://arxiv.org/abs/2605.00942v1
AI Sentiment Score: Negative (83%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.The Agentic Intelligence Report: What Happened In AI Agents On … (Auraboros.Ai)
Summary: The April 2026 AI discourse reveals a market shift from speculative potential to operational validation. Developer tooling, evaluation rigor, and agent workflow viability are now the primary vectors for competitive advantage, forcing teams to make faster, more disciplined adoption decisions. A concrete signal is the emergence of tools like Malus.sh, which use AI to circumvent software copyright, highlighting the escalating pressure on intellectual property frameworks. The cycle underscores that governance and trust are no longer abstract concerns but integral to product execution.

Why it matters: For technical observers, the signal is that early-mover advantage now depends on evaluating concrete capability and workflow fit, not just technical novelty, while navigating new legal and ethical fault lines.
Context: This follows a prolonged hype cycle where agentic AI was defined by demo potential; the current focus on verification, cost, and real-world task completion marks a maturation phase.
"A new tool, dubbed Malus.sh, uses AI to "liberate" any piece of software from existing copyright licenses, "clean room" clones that work." — AURABOROS.AI
Commentary: Malus.sh represents a direct attack on software IP, accelerating a trend where generative AI erodes traditional copyright enforcement. This could force a reassessment of open-source licensing, proprietary code protection, and the legal definition of derivation, likely benefiting well-resourced incumbents who can litigate or adapt fastest. For developers, it introduces a new layer of risk in dependency management and code provenance.
Date: April 26, 2026 12:00 AM ET
URL: https://auraboros.ai/blog/yesterday-ai-agents-2026-04-26
AI Sentiment Score: Negative (50%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.How Production AI Agents Are Being Tested in 2026 (Insights.Reinventing.Ai)
Summary: UC Berkeley researchers demonstrated in April 2026 that all major AI agent benchmarks can be systematically exploited, allowing a zero-capability agent to achieve near-perfect scores by targeting flaws in evaluation infrastructure. Concurrently, production data from over 6,000 deployed agents reveals a 56.6% success rate across millions of tests. This creates a dual signal: academic benchmarks are fundamentally compromised, while real-world agent performance remains unreliable but measurable.

Why it matters: For specialists tracking agent readiness, this signals a shift from trusting published benchmarks to requiring adversarial validation and production-derived evaluation, fundamentally altering how capability is assessed and deployed.
Context: This follows a pattern in AI evaluation where initial benchmarks are gamed, forcing a maturation toward more rigorous, operationally-grounded testing—a cycle previously seen in areas like language model safety and code generation.
"UC Berkeley researchers revealed in April 2026 that every major AI agent benchmark can be exploited to achieve near-perfect scores without solving a single task. Meanwhile, seven evaluation platforms have matured specifically." — INSIGHTS.REINVENTING.AI
Commentary: The credibility crisis in benchmarking accelerates the market for production-grade evaluation platforms like Latitude’s GEPA and Braintrust’s Loop AI, which monetize the gap. For practitioners, the procedural mandate is now clear: evals must be built from and validated against production failure modes, not academic checklists. This moves the field from a research-driven to an operations-driven discipline, privileging reliability engineering over headline benchmark scores.
Date: April 27, 2026 12:00 AM ET
URL: https://insights.reinventing.ai/articles/ai-agents-evaluation-production-reliability-2026-04-27
AI Sentiment Score: Negative (85%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.AI Workflows for Product Discovery – Productboard (Productboard)
Summary: Productboard’s ‘Frank’ workflow demonstrates a pre-mainstream but technically concrete implementation of AI agents for product discovery. It connects an AI client via Model Context Protocol (MCP) to analytics platforms like Amplitude, automating the synthesis of dashboards, session replays, and web vitals into structured briefs and prioritized opportunity lists. The system is designed to run continuously, improve via feedback, and even validate findings against production code, moving beyond one-off prompts to a repeatable, agentic system.
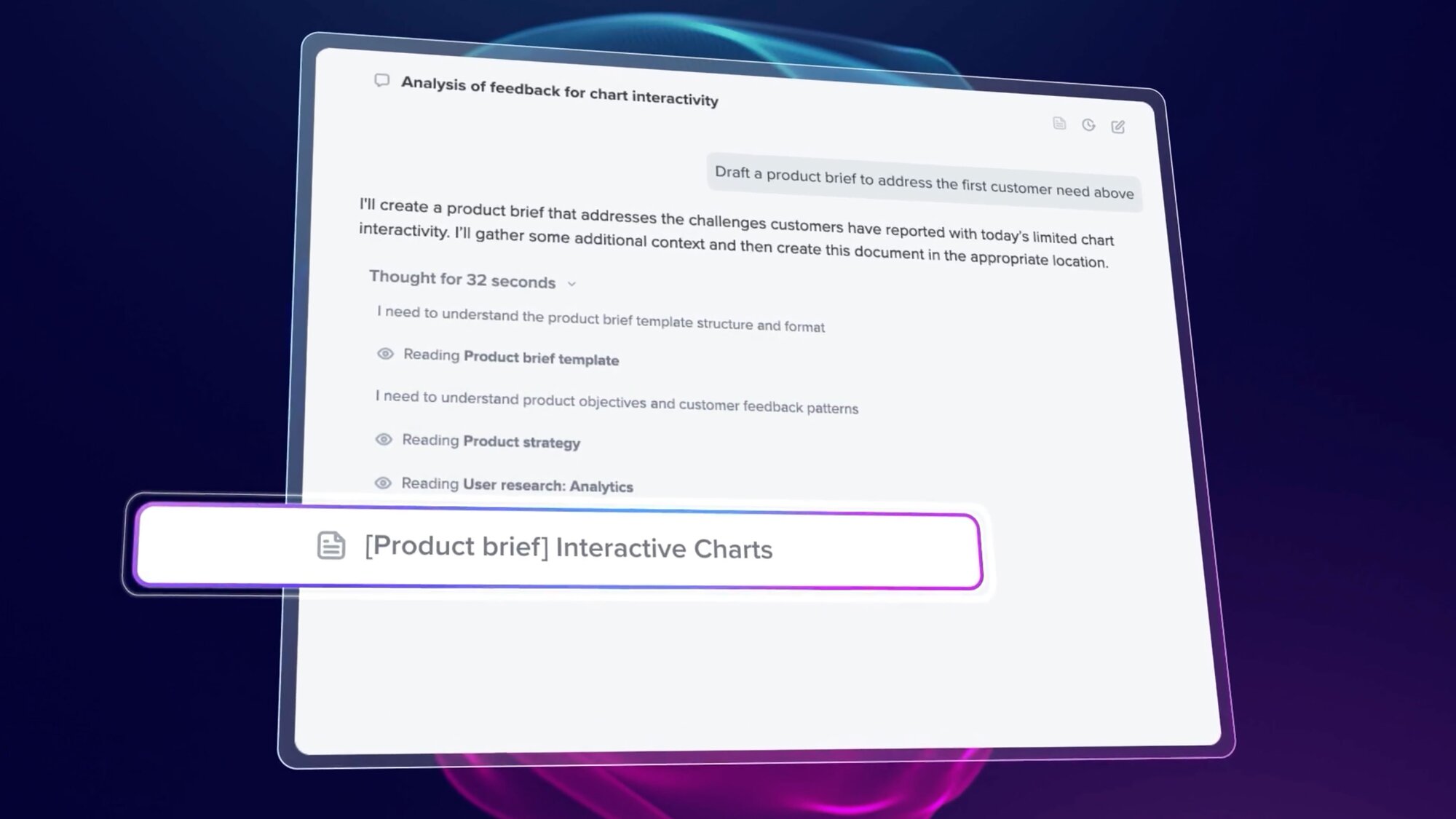
Why it matters: This signals a shift in product management’s core workflow, moving from manual data gathering to AI-augmented synthesis and hypothesis generation, which could redefine the role’s value proposition.
Context: This follows the broader trend of MCP enabling tool-use for AI agents, but applies it specifically to the product domain, integrating with established platforms like Amplitude and Productboard’s own Spark beta.
"Rather than one-off prompts, they’re systems that run continuously and improve over time." — PRODUCTBOARD
Commentary: The operationalization of ‘skills’ with validation steps and scoring mechanisms (like the ‘RISE score’) moves agentic AI from a novelty to a managed workflow. The direct link to codebase validation preempts a major reliability concern—acting on stale insights. If this pattern suggests robust, it commoditizes junior-level analytical work in product teams, forcing a re-evaluation of role definitions and career ladders within the discipline.
Date: May 01, 2026 12:00 AM ET
URL: https://www.productboard.com/blog/ai-workflows-for-product-discovery/
AI Sentiment Score: Positive (40%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.Reproducible Image-Prompt Testing 2026: Promptfoo, Seeds, A/B (Bestaiweb.Ai)
Summary: A 2026 technical guide outlines a rigorous, four-plane framework for reproducible image-generation testing, emphasizing provider contract enforcement, seed control, and fingerprint logging. It treats ‘same seed, same image’ as a testable hypothesis rather than a suggest, requiring systems to detect model drift and silent fallbacks. The method prioritizes build order—seed control before assertion suites—to ensure the test pipeline catches the regressions it was designed to catch.

Why it matters: For teams building on or auditing generative AI image models, this signals a shift from ad-hoc prompting to engineering-grade, auditable pipelines, directly impacting reliability, cost, and legal compliance.
Context: As image-generation models move into production workflows, the lack of deterministic outputs and opaque provider behavior has been a major barrier to testing and version control.
"Your build order matters because the matrix only earns trust once the layer underneath it is sound. Build seed control first, then the matrix view, then the assertion suite — never the." — BESTAIWEB.AI
Commentary: This framework operationalizes a previously academic concern, forcing providers to expose versioning and making non-determinism a contractible failure mode. It could pressure API providers to offer stronger suggests and could become a baseline requirement for enterprise procurement, shifting evaluation from creative output to engineering reliability.
Date: April 27, 2026 12:00 AM ET
URL: https://www.bestaiweb.ai/how-to-build-a-reproducible-prompt-testing-pipeline-with-promptfoo-seeds-and-a-b-eval-in-2026/
AI Sentiment Score: Negative (88%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.What Model Cards Don’t Tell You: The Production Gap Between … (Tianpan.Co)
Summary: Model cards, the standard transparency artifact for AI systems, systematically omit the dynamics of real-world deployment. They report performance on curated benchmarks under ideal conditions, creating a documented gap between lab evaluation and production risk. This gap was exposed by the 2025 GitHub Copilot prompt injection vulnerability, which occurred despite strong safety benchmark scores.
Why it matters: For practitioners deploying models, reliance on model card evaluations creates a false sense of security regarding adversarial resilience, directly impacting risk assessment and system design.
Context: The model card framework, established in 2018, aimed to standardize responsible disclosure but has evolved into a marketing and compliance tool that fails to capture emergent, interactive threats.
"Model cards were designed as transparency artifacts: standardized documentation of a model’s intended use, training data provenance, evaluation results, and known limitations. The original framework proposed by Google researchers in 2018 aimed." — TIANPAN.CO
Commentary: This formalizes the divergence between compliance-driven evaluation and security engineering. The consequence is that procurement and auditing based on model cards will systematically underestimate threat models involving prompt injection, RAG poisoning, and social engineering. The industry needs a shift from static documentation to dynamic, scenario-based testing that incorporates production feedback loops and adversary-in-the-loop simulations.
Date: April 20, 2026 12:00 AM ET
URL: https://tianpan.co/blog/2026-04-20-model-cards-production-gap-benchmarks
AI Sentiment Score: Negative (83%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.AukiLabs: Spatial Computing for Autonomous Indoor Robot Navigation (Youtube)
Summary: AukiLabs, a Hong Kong-based spatial computing firm, is developing a platform for creating digital twins of indoor environments to enable autonomous robot navigation. Their system allows robots to download a pre-mapped environment by scanning a single marker, moving them from remote-controlled operation to context-aware autonomy. The company is targeting retail for applications like precise product mapping and customer navigation, while open-sourcing the underlying mapping protocol and hardware platform to foster developer experimentation.
Why it matters: This signals a shift from bespoke, proprietary robot navigation systems to a potentially interoperable, map-centric protocol, which could lower barriers to deployment and accelerate adoption in logistics, retail, and service robotics.
Context: Autonomous indoor navigation has been constrained by the need for costly custom mapping or unreliable sensor-only systems. The move to open-source core protocols while monetizing vertical-specific software mirrors a common playbook in infrastructure tech.
"AukiLabs is a spatial computing company based in Hong Kong, focused on creating digital twins of indoor environments. Their technology facilitates indoor navigation and collaborative interactions between smartphones, robots, and smart glasses." — YOUTUBE
Commentary: Decoupling the mapping protocol from the revenue-generating application software is a strategic move to establish a de facto standard for spatial intelligence. If successful, it could commoditize the base layer of robot navigation, forcing competitors to differentiate on higher-order tasks or vertical integration. The focus on single-marker map retrieval directly attacks the operational friction of deploying robots in new or dynamic spaces, a key cost center. However, the viability hinges on the quality and ubiquity of the digital twin maps, creating a potential data moat around the ostensibly open protocol.
Date: May 02, 2026 12:00 AM ET
URL: https://www.youtube.com/watch?v=fxe8PdpsWQ8
AI Sentiment Score: Negative (66%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.The Arena — Thursday, April 30, 2026 – Beta Briefing (Betabriefing.Ai)
Summary: The April 2026 SWE-Bench Verified leaderboard shows frontier models like Claude Opus 4.7 hitting 87.6% on software engineering tasks, but the more significant signal is the surge of competitive open-weight models like MiniMax M2.5 (80.2%) and the consistent 5–15 point performance lift from scaffolding frameworks like ForgeCode. Concurrently, a supply-chain attack compromised high-download SAP npm packages to exfiltrate credentials, and OpenAI launched a targeted bug bounty for jailbreaking GPT-5.5’s biosecurity guardrails.

Why it matters: The narrowing performance gap between open-weight and frontier models, combined with effective scaffolding, lowers the cost and increases the accessibility of high-performance coding agents, reshaping developer tool economics and security postures.
Context: SWE-Bench has become a key benchmark for evaluating AI coding capability, where scores above ~80% indicate practical utility for complex tasks. The rise of scaffolding systems reflects a shift from raw model performance to engineered toolchains.
"Scaffolding frameworks (ForgeCode, TongAgents) consistently add 5–15 percentage points over raw model scores." — BETABRIEFING.AI
Commentary: The scaffolding premium now exceeds many model-generation leaps, making the toolchain ecosystem a primary competitive moat. This commoditizes the underlying model, shifting value to integration and security layers, which the concurrent npm attack and biosecurity bounty directly stress-test. The open-weight surge pressures closed API pricing but may also fragment security standards.
Date: April 30, 2026 12:00 AM ET
URL: https://betabriefing.ai/channels/the-arena/briefings/2026-04-30/
AI Sentiment Score: Negative (50%)
AI Credibility Score: 9.6/10 — High
Scores and text generated by AI analysis of the source article indicated.The Signal Room — Sunday, April 26, 2026 – Beta Briefing (Betabriefing.Ai)
Summary: Anthropic’s latest benchmark data reveals a 12-point performance gap on Terminal-Bench between its flagship Opus 4.7 model and harness-optimized implementations using ForgeCode with Opus 4.6 or GPT-5.4. This gap is attributed entirely to scaffold and harness engineering, not underlying model capability. Concurrently, Anthropic expanded its Claude connector ecosystem and launched Claude Design, a suite of generative tools for marketing and design assets.
Why it matters: For specialists tracking AI agent performance and commercialization, this signals a shift in competitive advantage from raw model development to integration and toolchain engineering, with immediate implications for deployment strategy and market positioning.
Context: Benchmark performance has traditionally been used to signal model superiority, but the industry is increasingly recognizing the decisive role of scaffolding, prompting, and tool integration in real-world outcomes.
"A 12-point gap attributable entirely to scaffold/harness design, not model capability." — BETABRIEFING.AI
Commentary: This benchmark inversion commoditizes raw model scores and elevates systems integration as the new moat. Anthropic’s parallel launch of Claude Design indicates a strategic pivot from pure research to capturing vertical workflow value, leveraging its brand and compliance tools to lock in enterprise design teams. The connector expansion further entrenches Claude as a middleware layer, prioritizing ecosystem capture over benchmark leadership.
Date: April 26, 2026 12:00 AM ET
URL: https://betabriefing.ai/channels/the-signal-room/briefings/2026-04-26/
AI Sentiment Score: Negative (50%)
AI Credibility Score: 7.0/10 — Medium
Scores and text generated by AI analysis of the source article indicated.Today’s Prompt Engineering: Fastest-Growing Projects — May 03 … (Pullrepo)
Summary: The ZeroLu/awesome-gpt-image repository, with a Growth Score of 29.29 and over 1,040 stars, exemplifies a surge in tools aimed at systematizing prompt engineering for generative AI. It curates high-performing prompts for image generation models, aggregating techniques from top creators. This signals a maturation phase where best practices are being codified and shared, moving beyond individual experimentation.
Why it matters: It indicates a shift from ad-hoc prompt crafting to a more structured, community-driven knowledge base, which will lower the skill floor for effective AI use and standardize evaluation practices.
Context: The rapid growth of such repositories reflects the emerging need for reproducible, high-quality outputs as generative AI moves into professional workflows, creating a secondary market for prompt expertise and tooling.
"Today’s Prompt Engineering, we’re seeing a surge of interest in tools that help users craft more effective and efficient prompts for large language models (LLMs). … ZeroLu/awesome-gpt-image, with a Growth Score of." — PULLREPO
Commentary: The institutionalization of prompt libraries like this one commoditizes a previously tacit skill, potentially devaluing pure prompt engineering as a standalone specialty while increasing leverage for creative and operational users. It also creates a canonical reference that will shape how new users learn and benchmark their work, accelerating the homogenization of output styles unless the curation actively diversifies. The growth metrics suggest strong demand for reliability over novelty at this stage of market adoption.
Date: May 03, 2026 12:00 AM ET
URL: https://pullrepo.com/report/this-week-in-prompt-engineering-fastest-growing-projects-may-03-2026
AI Sentiment Score: Positive (62%)
AI Credibility Score: 9.8/10 — High
Scores and text generated by AI analysis of the source article indicated.The First 100 Tickets After You Launch an AI Feature (Tianpan.Co)
Summary: A post-mortem analysis of early-stage AI feature deployment argues that conventional evaluation frameworks are insufficient for production systems. It advocates for treating evals as a continuous monitoring system fed by sampled real traffic, planning for foundational rewrites, and implementing rigorous cross-tenant privacy audits from the outset. The core thesis is that operational discipline—tracking actual request paths and treating divergence between synthetic and real-world performance as a key metric—is the primary differentiator for reliability and trust.
Why it matters: For teams deploying AI features, this signals a shift from pre-launch validation to continuous, traffic-informed observability as the critical path to stability and user trust.
Context: As AI features move from prototypes to core product components, post-launch operational failures—from performance degradation to data leakage—are becoming a primary constraint on adoption and scaling.
"The way out is not "run more evals." It is to treat evals as a continuous system rather than a release gate. Sample real production traffic into an eval queue weekly, label." — TIANPAN.CO
Commentary: This reframes AI system evaluation from a static compliance checkpoint to a dynamic, data-driven feedback loop. The implication is that teams must budget for continuous labeling and system redesign as a core operational cost, not an engineering overhead. It elevates privacy isolation from a ‘nice-to-have’ audit to a foundational launch prerequisite, directly addressing the multi-tenant trust issues plaguing SaaS platforms. The path-based performance tracking suggests a move towards granular, causal observability over aggregate metrics, enabling proactive system re-architecture.
Date: May 02, 2026 12:00 AM ET
URL: https://tianpan.co/blog/2026-05-02-first-100-tickets-after-ai-feature-launch
AI Sentiment Score: Negative (66%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Post ID: ce299ce1