Independent Operator & Newsletter Analysis
Why AI Data Agents Still Fail at Real Company Data (Medium)
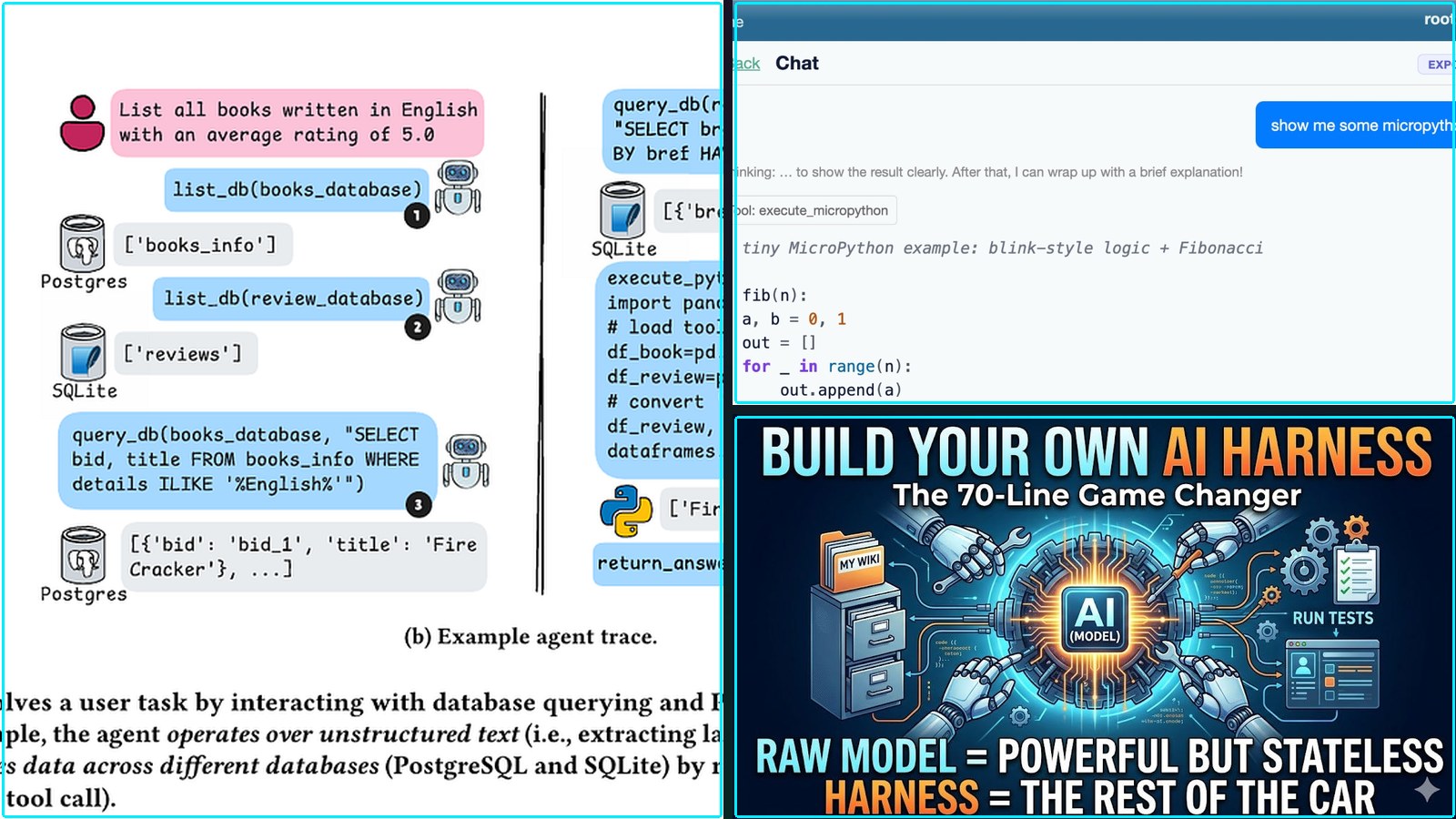
Summary: A new benchmark for AI data agents reveals a significant gap between the promise of natural-language business analytics and current performance. The DAB benchmark tests agents on messy, multi-database, real-world queries, where the best model achieves only a 38% success rate on its first attempt. Even with 50 retries, accuracy peaks below 70%, highlighting that the core challenge is not understanding the question but correctly executing the analysis on imperfect data.
Why it matters: For operators and analysts considering AI tools, this benchmark shifts the conversation from demos to operational risk, clarifying that the current value proposition is assistant-level, not autonomous.
Context: The AI data agent space has been dominated by smooth demos on clean datasets, creating expectations for a ‘no-SQL’ future. This research provides a concrete, adversarial test against the complexity of actual business data environments.
"Why AI Data Agents Still Fail at Real Company Data A new benchmark shows that asking questions in plain English is easy. Getting the right answer from messy business data is still." — MEDIUM
Commentary: The benchmark usefully reframes the problem: the failure mode is not bad SQL but flawed analytical reasoning, producing polished, plausible wrong answers. This forces a near-term product shift from ‘AI analyst’ to ‘assistant with automated checks,’ prioritizing verifiability over confidence. The cost-accuracy tradeoff, where the most accurate model is 20x more expensive, will shape commercial adoption, favoring layered systems that embed human review for high-stakes decisions.
Date: Thu, 04 Jun 2026 08:58:51 GMT
URL: https://medium.com/@davidpupaza3/why-ai-data-agents-still-fail-at-real-company-data-863086d6ac49
AI Sentiment Score: Negative (63%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Running Python code in a sandbox with MicroPython and WASM (Simonwillison.Net)
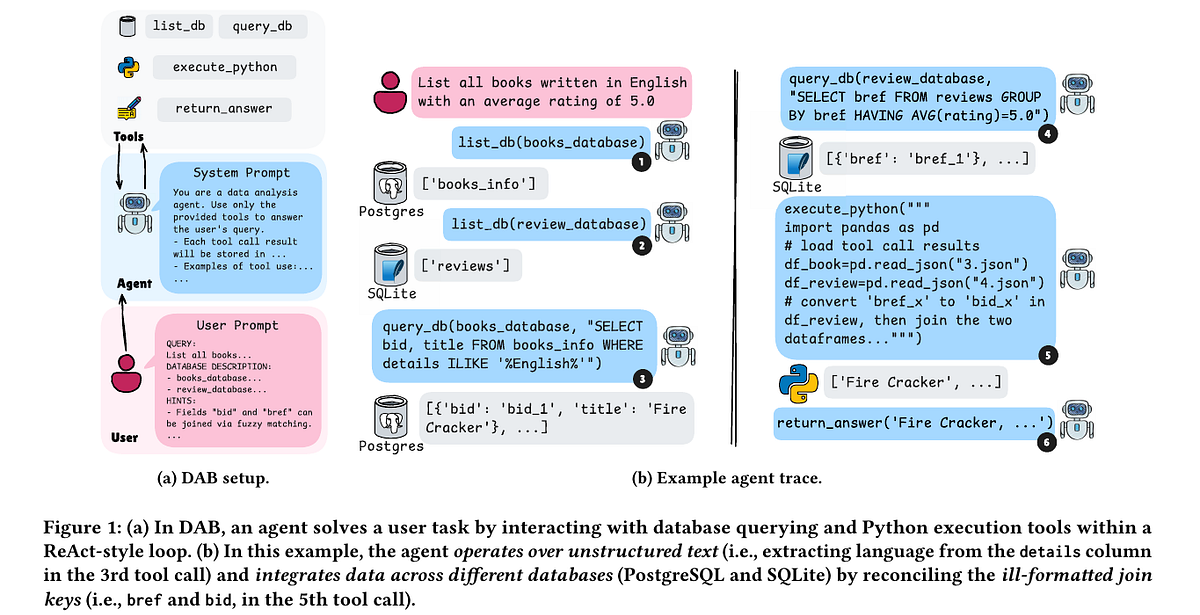
Summary: Simon Willison has released an alpha Python package, micropython-wasm, which uses a WebAssembly-compiled MicroPython interpreter to execute Python code within a sandboxed environment from a host Python application. The system aims to provide a secure, embeddable plugin runtime with controlled resource access, addressing a long-standing need in his open-source projects like Datasette. The implementation leverages wasmtime for WebAssembly execution and includes mechanisms for persistent interpreter state and controlled exposure of host functions.
Why it matters: For independent operators building extensible software, a robust, easy-to-deploy sandbox for plugins or user code mitigates a major security and stability risk, enabling more ambitious features without compromising core application integrity.
Context: Sandboxing dynamic language code in server-side applications remains a notoriously difficult problem, with many past solutions being abandoned or deemed unsafe. WebAssembly offers a promising, battle-tested foundation, but practical, maintainable embeddings for Python have been scarce.
"WebAssembly sure feels like a constrained environment to me!" — SIMONWILLISON.NET
Commentary: Willison’s prototype is valuable as field observation and a concrete argument worth testing: it demonstrates a pragmatic path to sandboxing by combining mature, low-level WebAssembly tooling with a lightweight interpreter. Its success hinges not on novelty but on whether it can attract the institutional support and rigorous security review he openly solicits, moving from a ‘vibe-coded’ proof-of-concept to a trusted component.
Date: June 05, 2026 11:53 PM ET
URL: https://simonwillison.net/2026/Jun/6/micropython-in-a-sandbox/
AI Sentiment Score: Negative (50%)
AI Credibility Score: 10.0/10 — High
Scores and text generated by AI analysis of the source article indicated.I Built My Own AI Harness (and Finally Understood the Tools I Use Every Day) (Javascript.Plainenglish.Io)
Summary: I Built My Own AI Harness (and Finally Understood the Tools I Use Every Day) Let me confess something embarrassing for someone who codes with AI all day. I run Claude Code and Codex every single day. They read my files, run my tests, edit ten things at once, and somehow Just Work.

Why it matters: This matters for Independent Operator & Newsletter Analysis because it gives a concrete current signal to track: I Built My Own AI Harness (and Finally Understood the Tools I Use Every Day) Let me confess something embarrassing for someone who codes with AI all day.
Context: I Built My Own AI Harness (and Finally Understood the Tools I Use Every Day) Let me confess something embarrassing for someone who codes with AI all day. I run Claude Code and Codex every single day. They read my files, run my tests, edit ten things at once, and somehow Just Work.
"I Built My Own AI Harness (and Finally Understood the Tools I Use Every Day) Let me confess something embarrassing for someone who codes with AI all day. I run Claude Code." — JAVASCRIPT.PLAINENGLISH.IO
Commentary: The immediate test is whether this becomes repeatable operator practice rather than another surface-level workflow claim.
Date: Thu, 04 Jun 2026 09:20:04 GMT
URL: https://javascript.plainenglish.io/i-built-my-own-ai-harness-and-finally-understood-the-tools-i-use-every-day-dcebf4449f5a
AI Sentiment Score: Negative (75%)
AI Credibility Score: 8.0/10 — High
Scores and text generated by AI analysis of the source article indicated.Post ID: 7a73475c